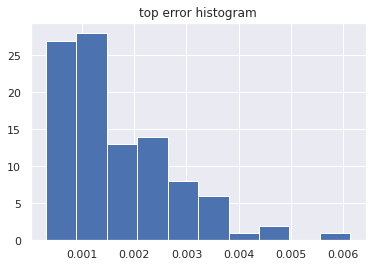
About 20 percent of the rows account for 75 percent of the total error.
Worst scores due to bad stocks or bad time_ids? When comparing errors aggregated over stocks and errors aggregated over time_ids, the time_ids show a much higher variance than stock_ids. This could be due to fast changing shocks to the market, imposed on all stocks at once. We could possibly detect these shocks if they occur in the last minute or two of the input data window.
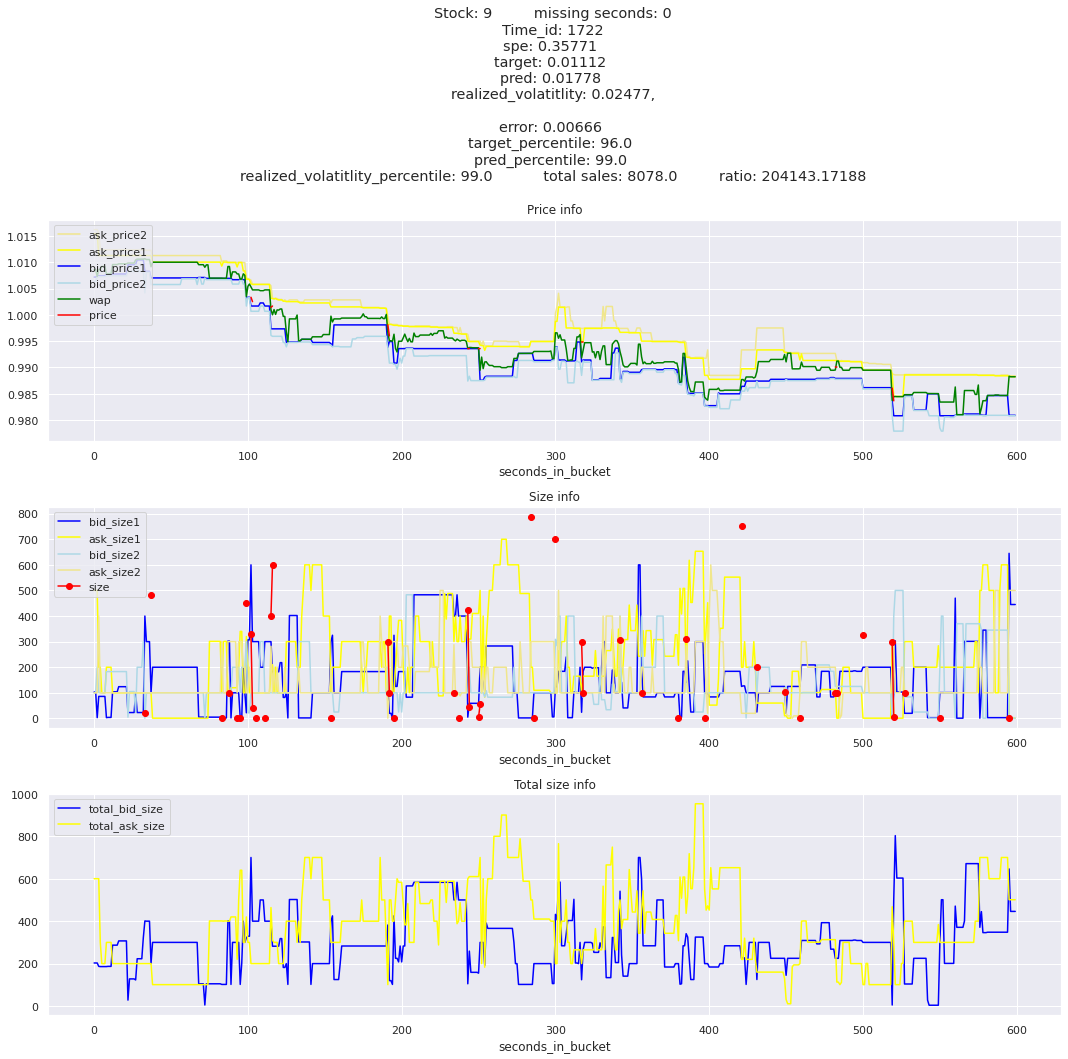
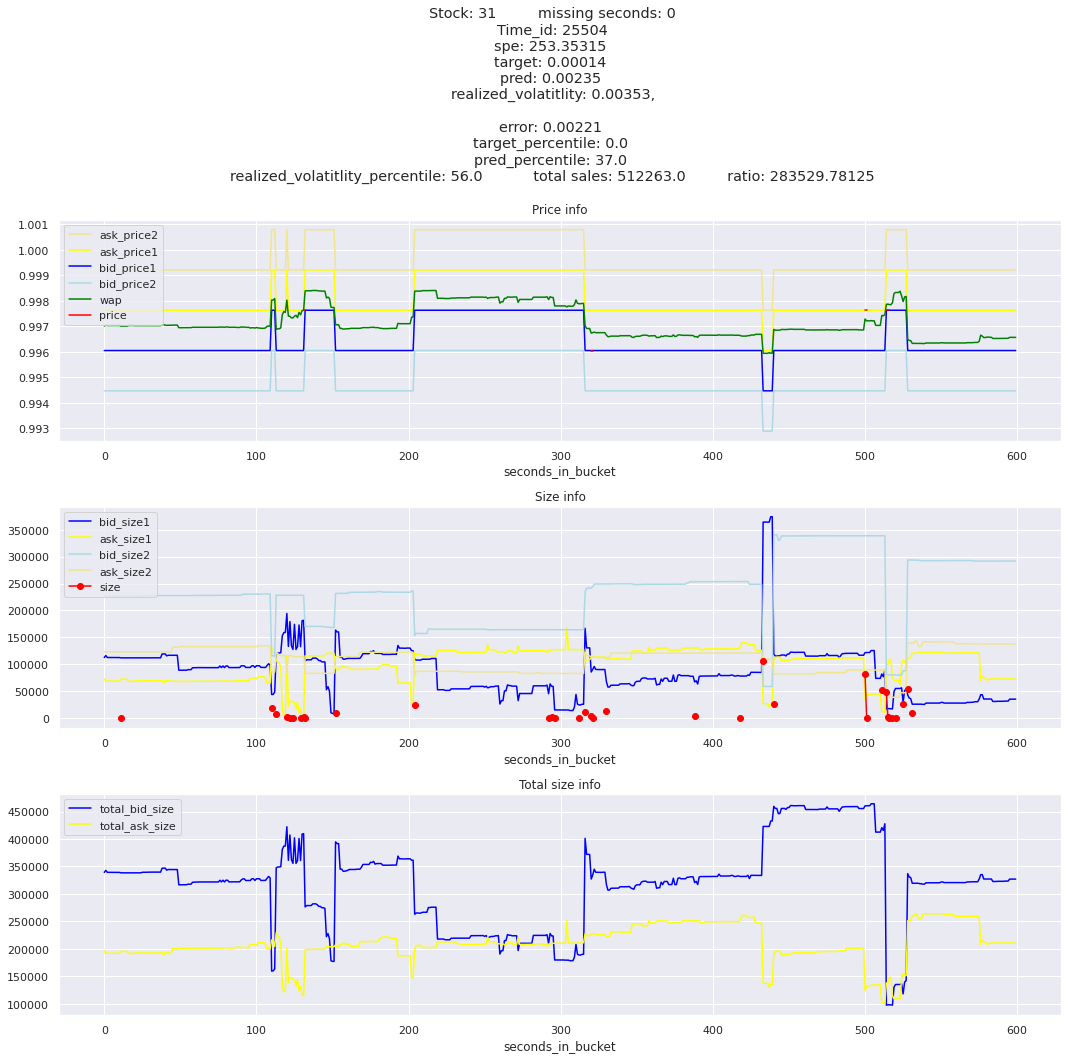
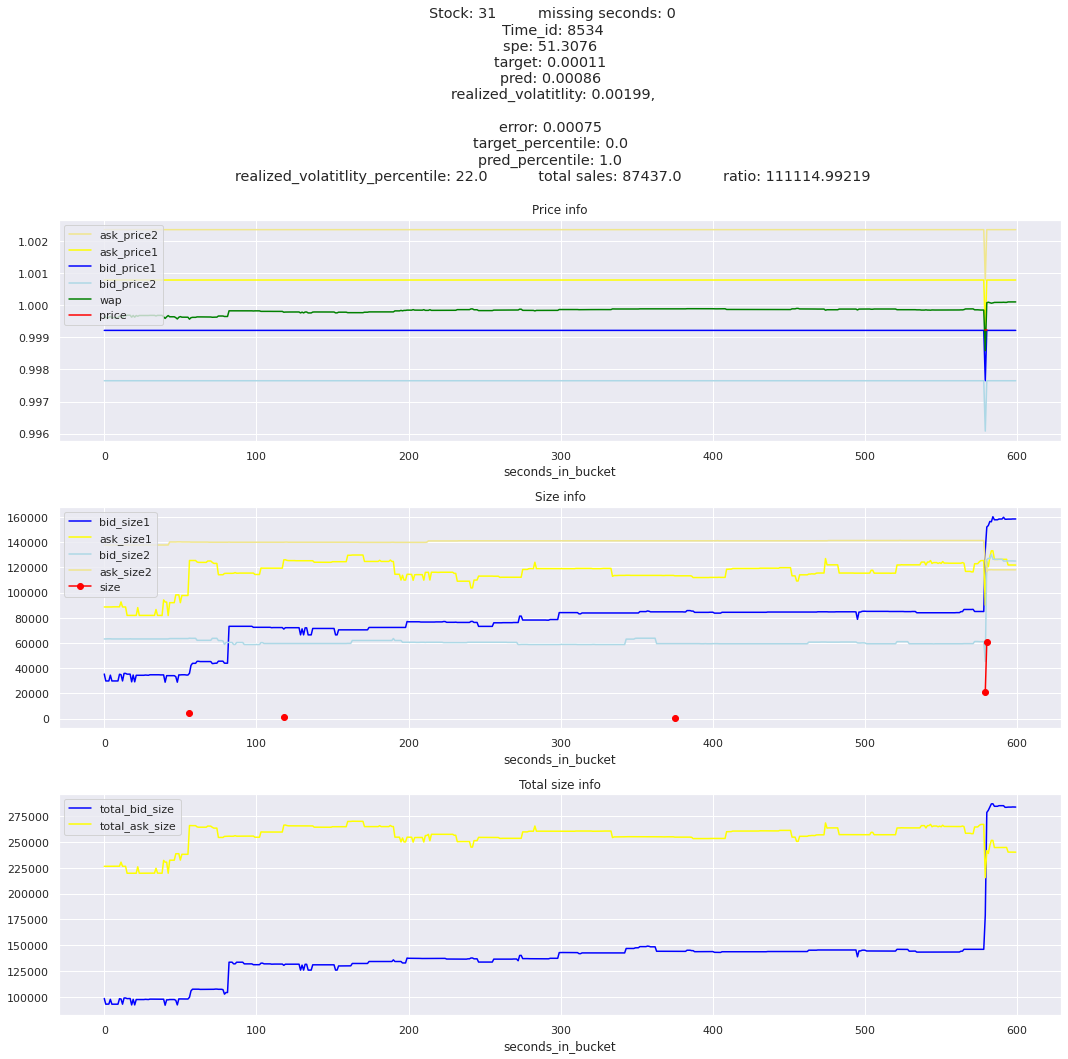
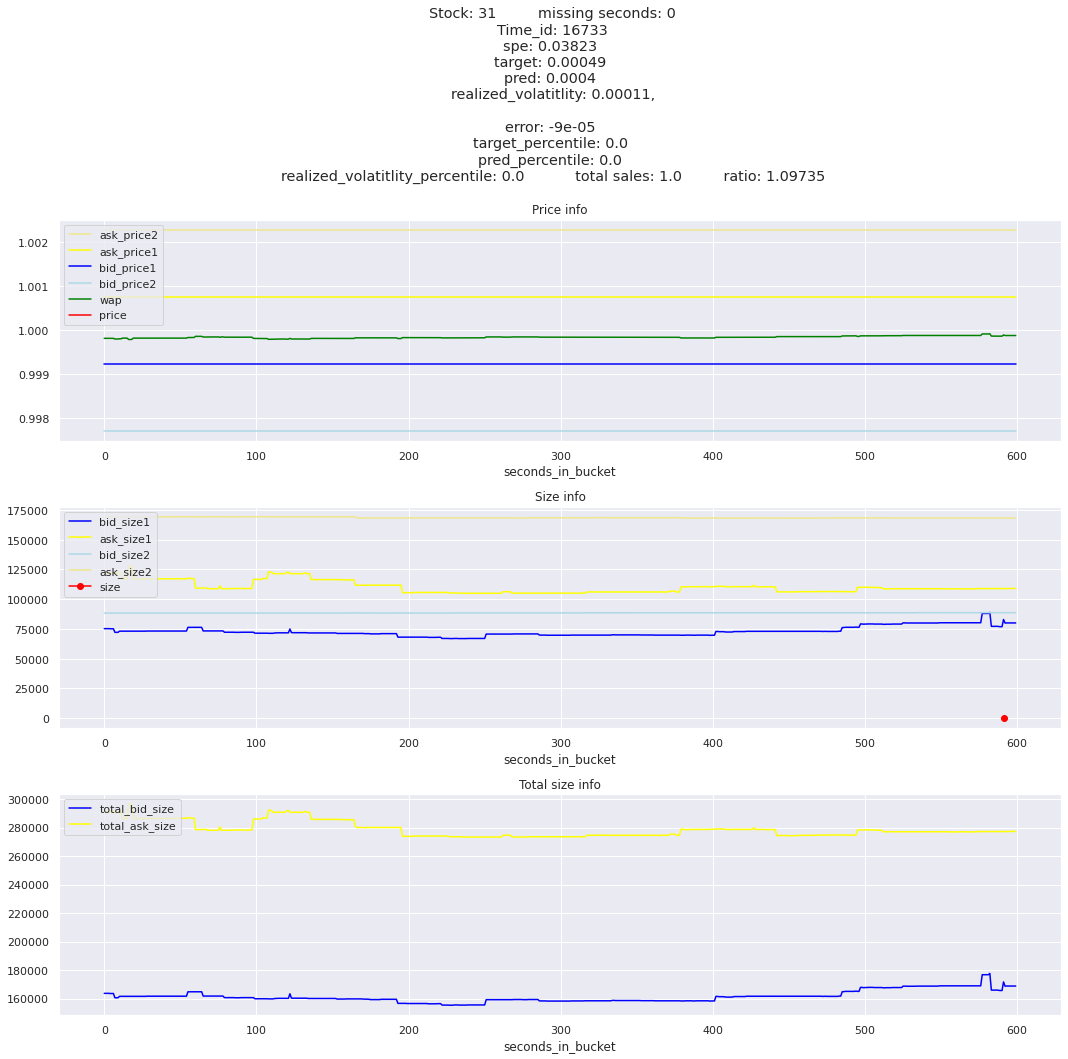
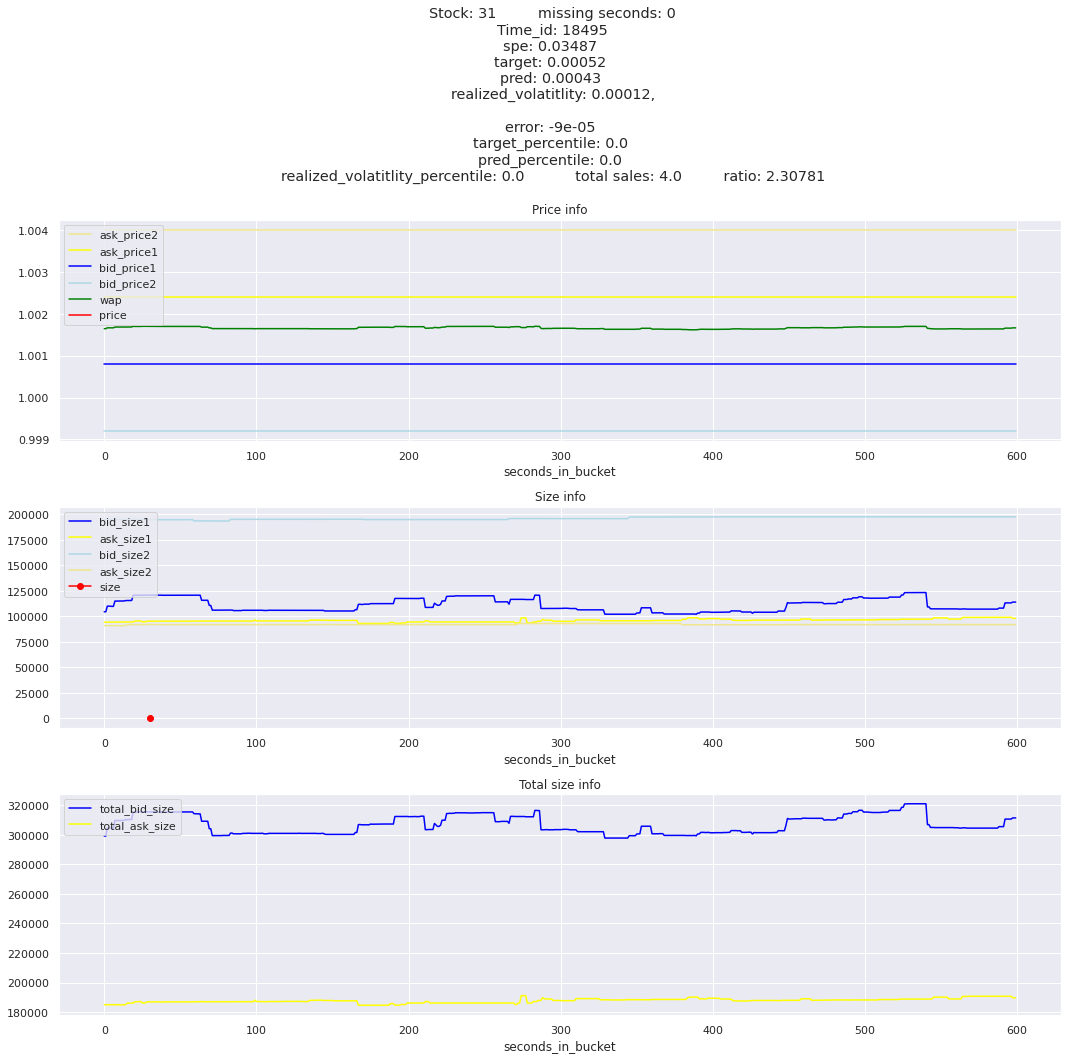
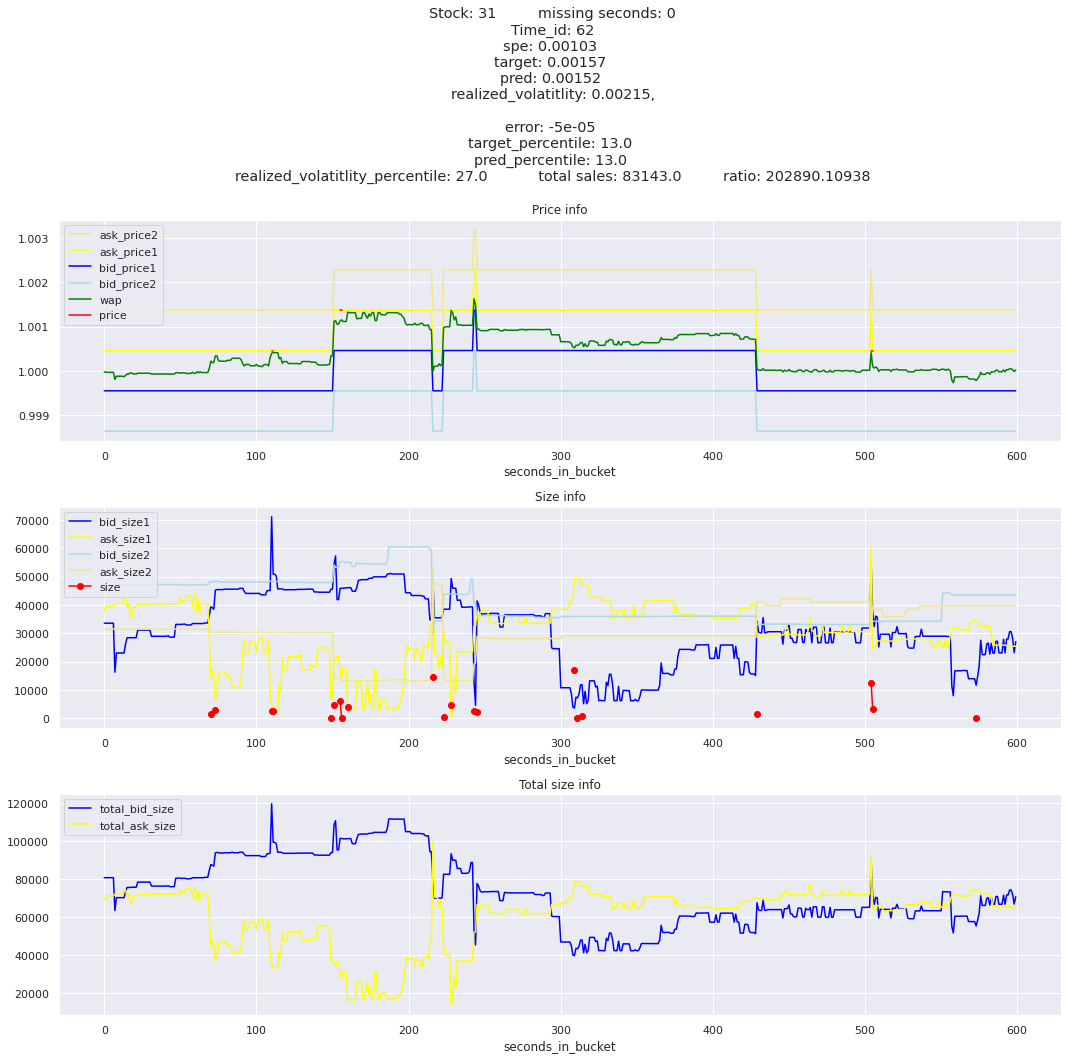
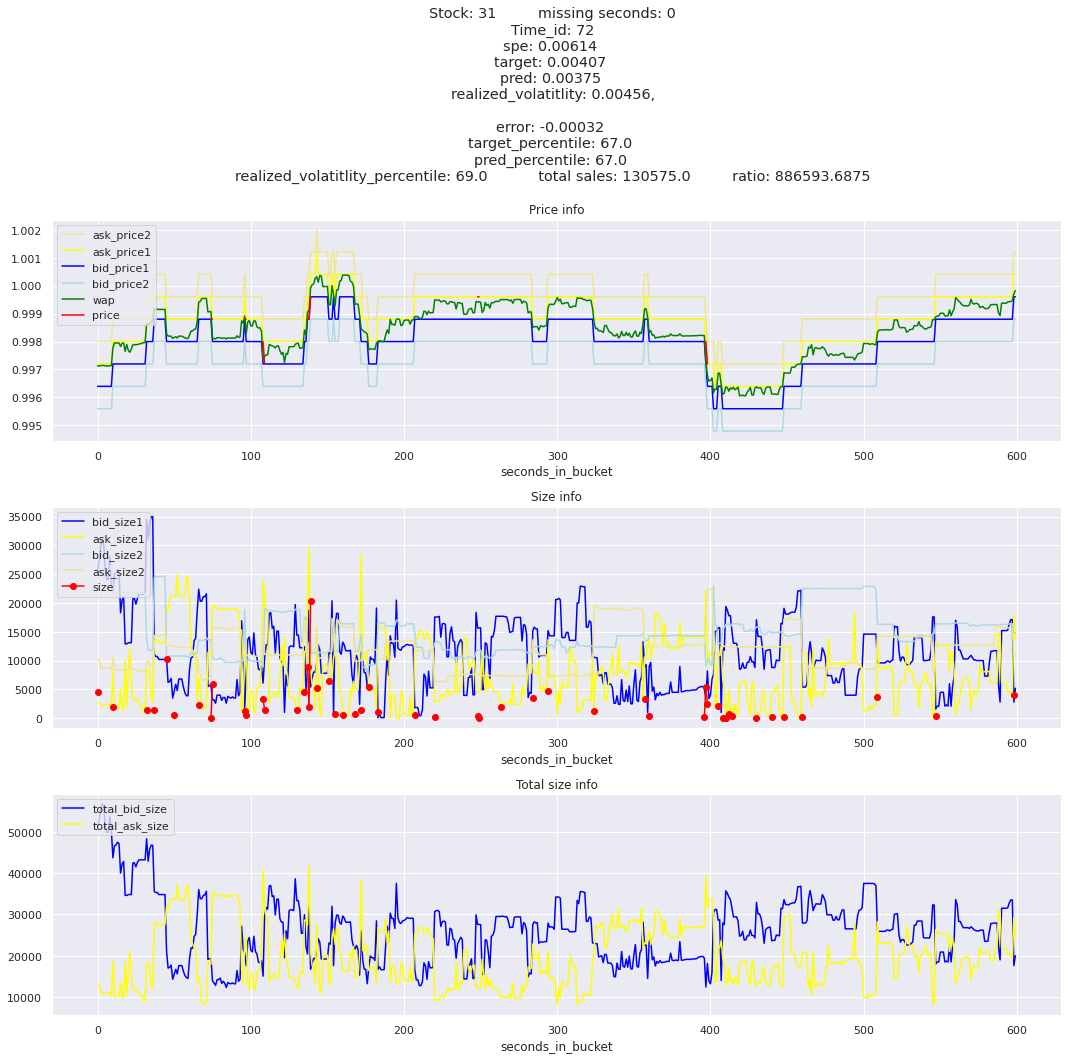
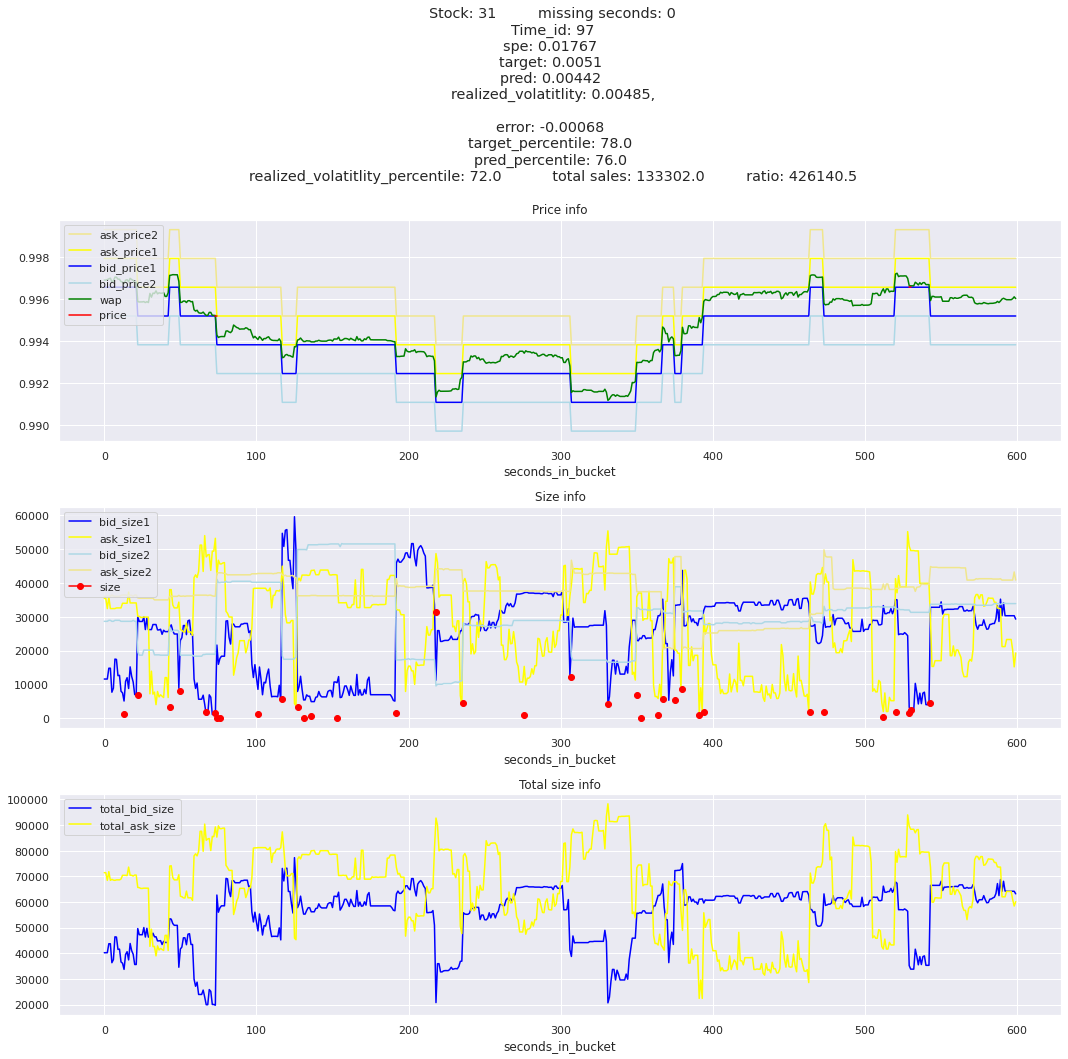
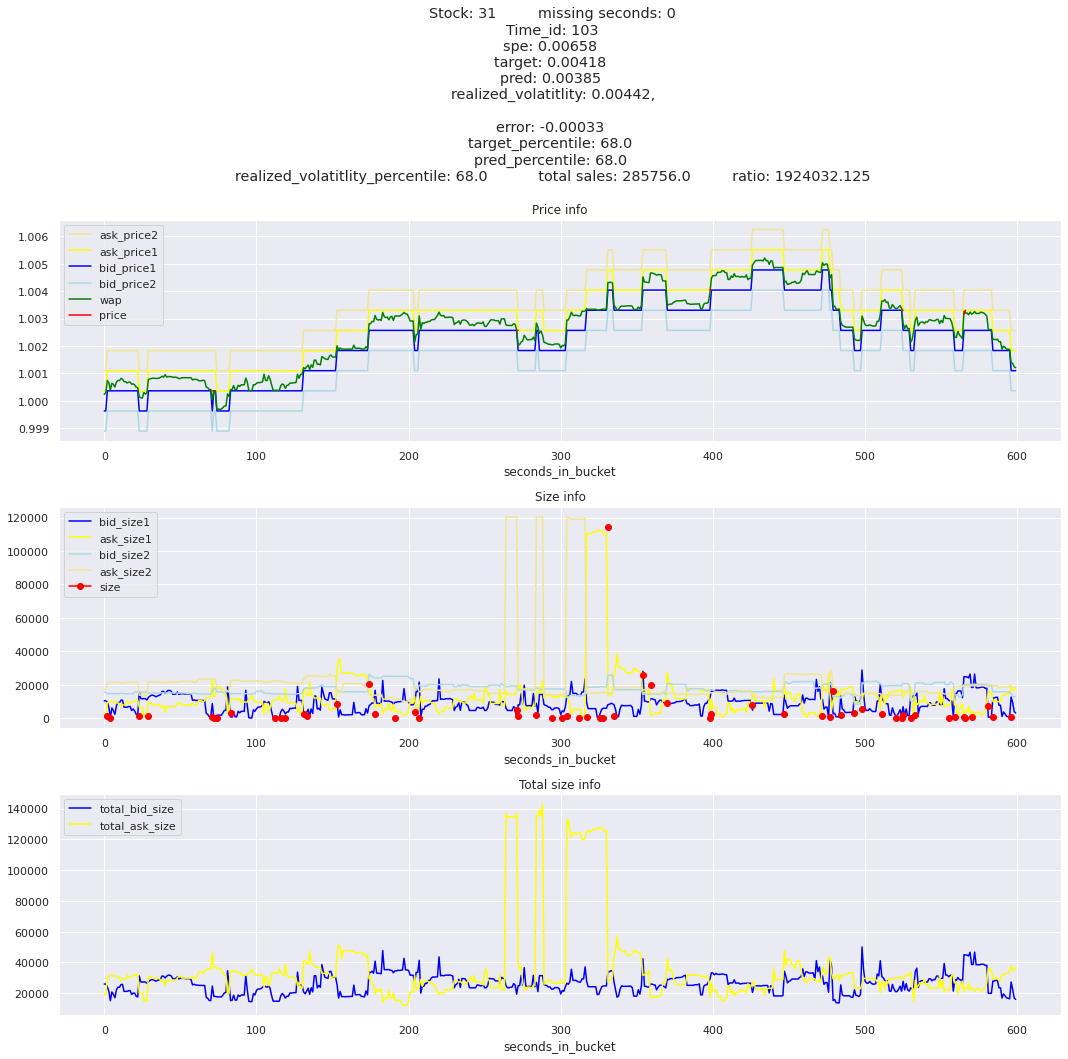
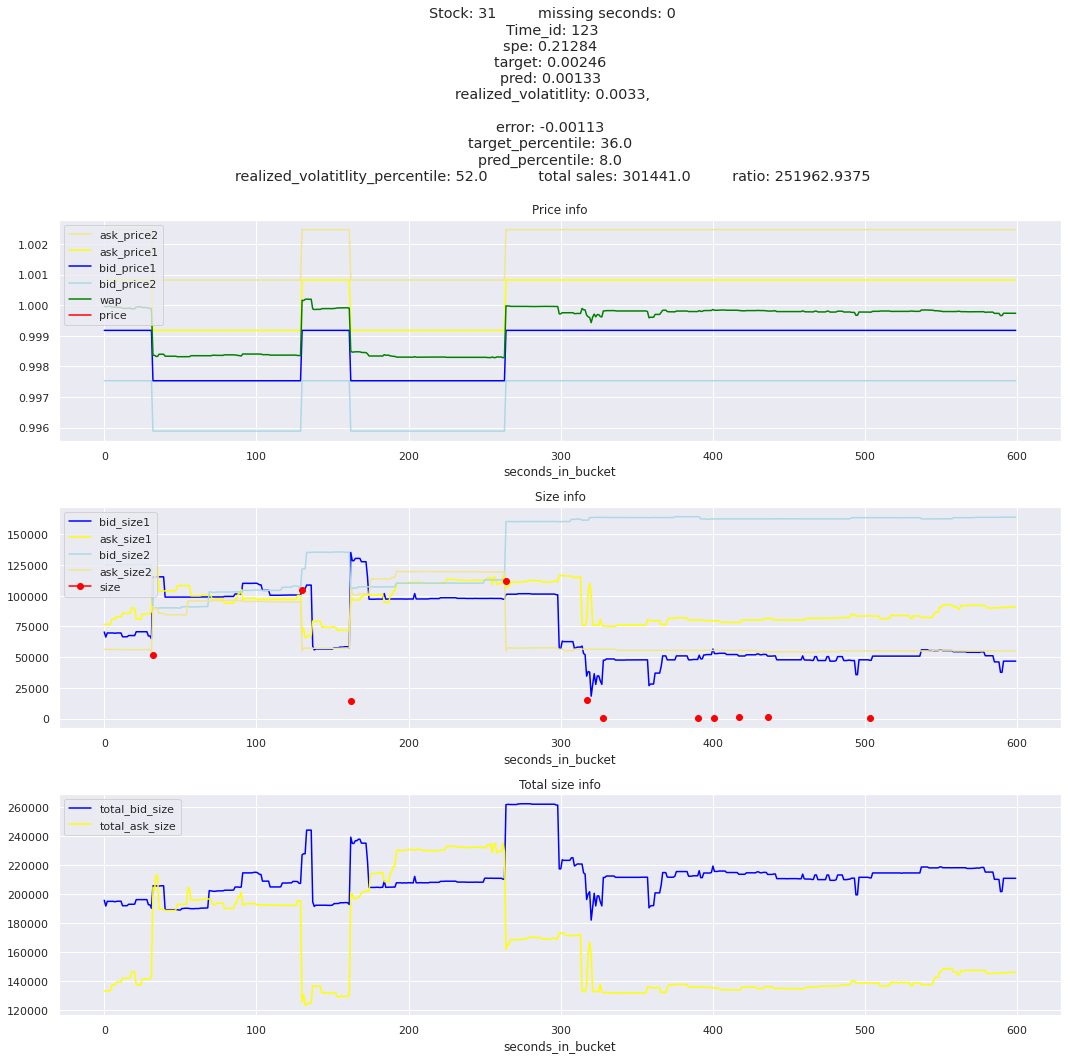
The worst scoring time_id is 25504 and the worst scoring stock is stock_31.
The worst scoring rows are usually due to an extremely low target, since the target is used as a divisor in the competition metric, the rmspe. From the plots I have made, I cannot see any clear signals that could warn me of an extremely low target.
Action to take: Look for aggregations across time_ids that could possibly help our models detect periods of low targets.
Lets read in our predictions and calculate the squared percentage error for analysis
/home/c/miniconda3/envs/opt_nb/lib/python3.7/site-packages/ipykernel_launcher.py:4: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
after removing the cwd from sys.path.
/home/c/miniconda3/envs/opt_nb/lib/python3.7/site-packages/ipykernel_launcher.py:5: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
"""
/home/c/miniconda3/envs/opt_nb/lib/python3.7/site-packages/ipykernel_launcher.py:6: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
What is the general distribution of errors? Are they low or high variance?
If They have high variance, with a few very large errors, we may be able to identify some way of easily reducing these errors, which would have a large impact on our overall score.
sns.kdeplot(train['spe'])plt.title('squared percentage error kernel density plot')plt.show()
What the heck. This looks like I have one or a few large errors and most near zero.
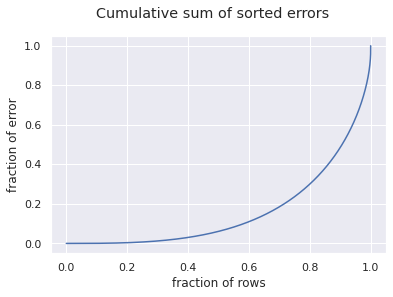
Lets look at the cumulative sum of errors to see how spread out the errors are.
df = train['spe'].sort_values().cumsum().reset_index(drop=True)df.index /= df.index.values[-1]df /= df.max()df.plot()plt.suptitle('Cumulative sum of sorted errors')plt.xlabel('fraction of rows')plt.ylabel('fraction of error')plt.show()
It looks like the last 20% of the rows carry about 75% of the error.
Comparing stock_id and time_id group error distribution
Lets see if the error is balanced accross stock_ids and time_ids.
Stock_id
print('Errors by stock_id sorted in descending order')stock = train.groupby('stock_id')['spe'].sum()stock.sort_values(ascending=False)
I was expecting the minimum to be much much lower compared to the maximum spe stock_id. The worst offender, stock_id 31 is only about 3 times worse than the second at 380 and gradually goes down to around 100 for the lowest stock. So stock 31 needs a little special attention, but we need to look at all stocks erros. I am guessing that the time_id aggregations won’t be as balanced.
I am curious to see how the correlation between the target and log_return_realized_volatility (the most standard predictor) compares between the best and worst scoring stock.
I was correct about time_id group score being more spread than stock_id. The worst time id is about 250 times as bad as the best scoring time_id.
I am curious to see how the correlation between the target and log_return_realized_volatility (the most standard predictor) compares between the best and worst scoring time_id.
Similar to stock_id, the best time_id group has a higher correlation.
A further look at the worst time_ids: plotting realized volatility, target, and prediction for all stocks
top_5_worst_times = worst_times[:5].index
There is a great imbalance here, with the top time_id accruing about 200 times the error of the bottom. If we can identify the reason for these errors in the hardest hit time ids, we have the best chance to improve our models.
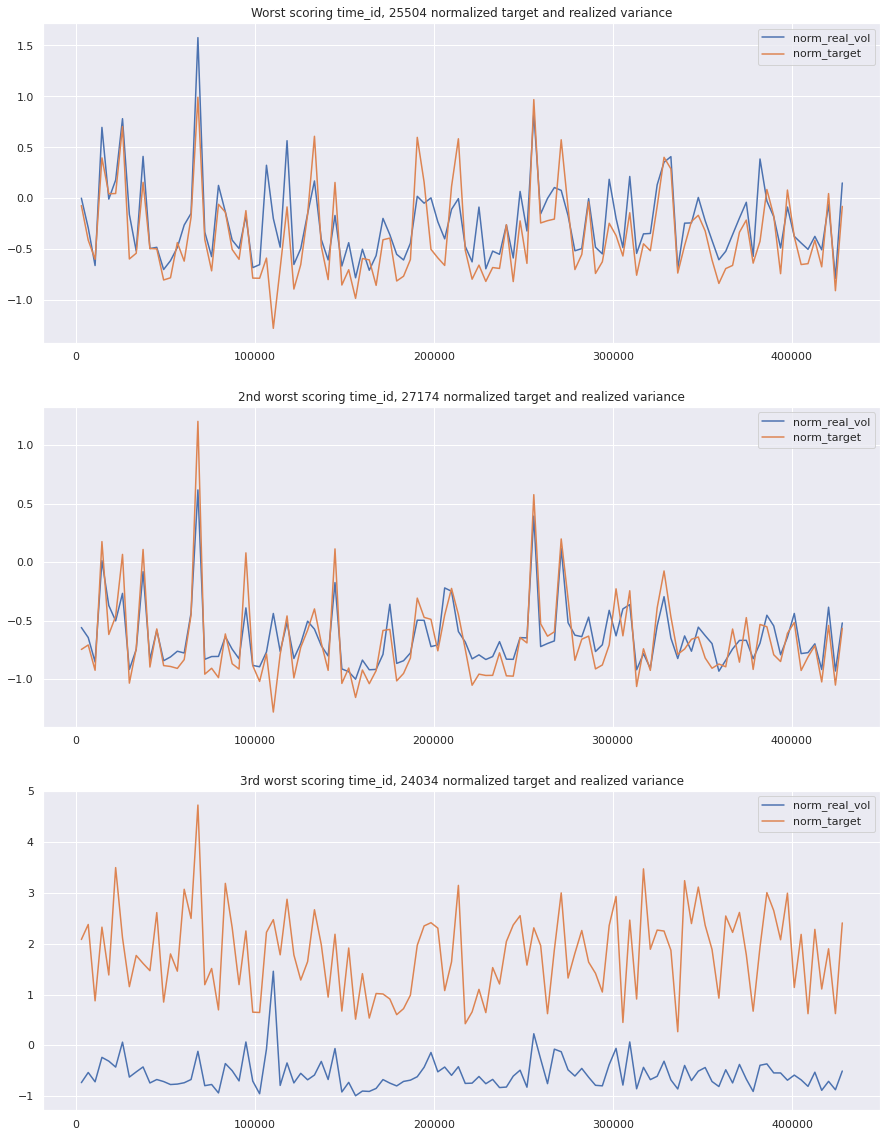
I am suspecting that either the first 10 minute window is low volatitliy, followed by a second 10 minute window with high volatility, or vica versa. For the top time_id, 25504, lets see how the realized volatility compares to the average of the first 10 minutes, and then how the target compares to the average target.
Lets normalize the target and realized volatility of the the first 10 minutes. This way we put the variables on the same scale that is used when calculating correlation between variables.
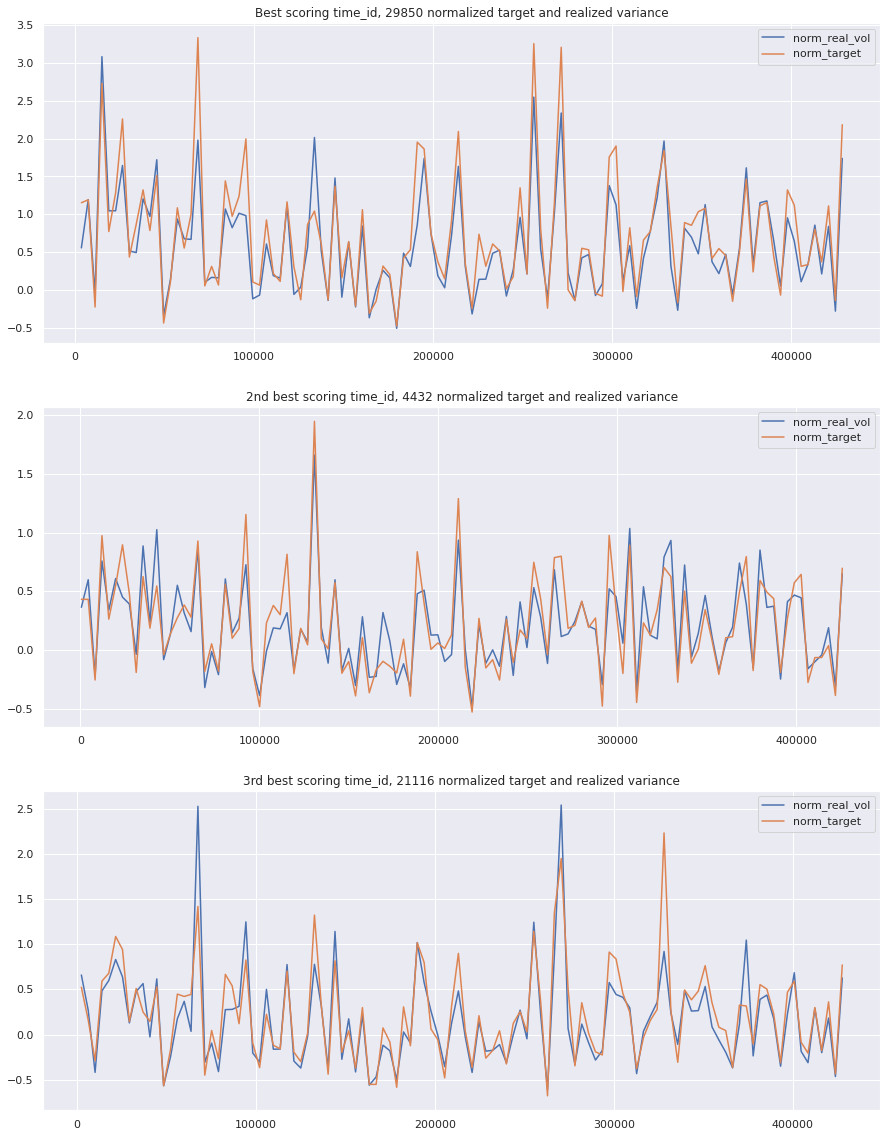
fig, axes = plt.subplots(3, 1, figsize=(15, 20))train[train.time_id ==29850][['norm_real_vol', 'norm_target']].plot(ax=axes[0])axes[0].set_title('Best scoring time_id, 29850 normalized target and realized variance')train[train.time_id ==4432][['norm_real_vol', 'norm_target']].plot(ax=axes[1])axes[1].set_title('2nd best scoring time_id, 4432 normalized target and realized variance')train[train.time_id ==21116][['norm_real_vol', 'norm_target']].plot(ax=axes[2])axes[2].set_title('3rd best scoring time_id, 21116 normalized target and realized variance')plt.show()
I am a bit confused. The 3rd worst scoring time_id looks really bad, but the first 2 look almost like best scoring time_ids. Maybe there is something I can’t see yet that is hurting my model. Lets plot the same plots again, along with our predictions. We will have to scale the predictions with the the same mean and std of the target to put them on the same scale.
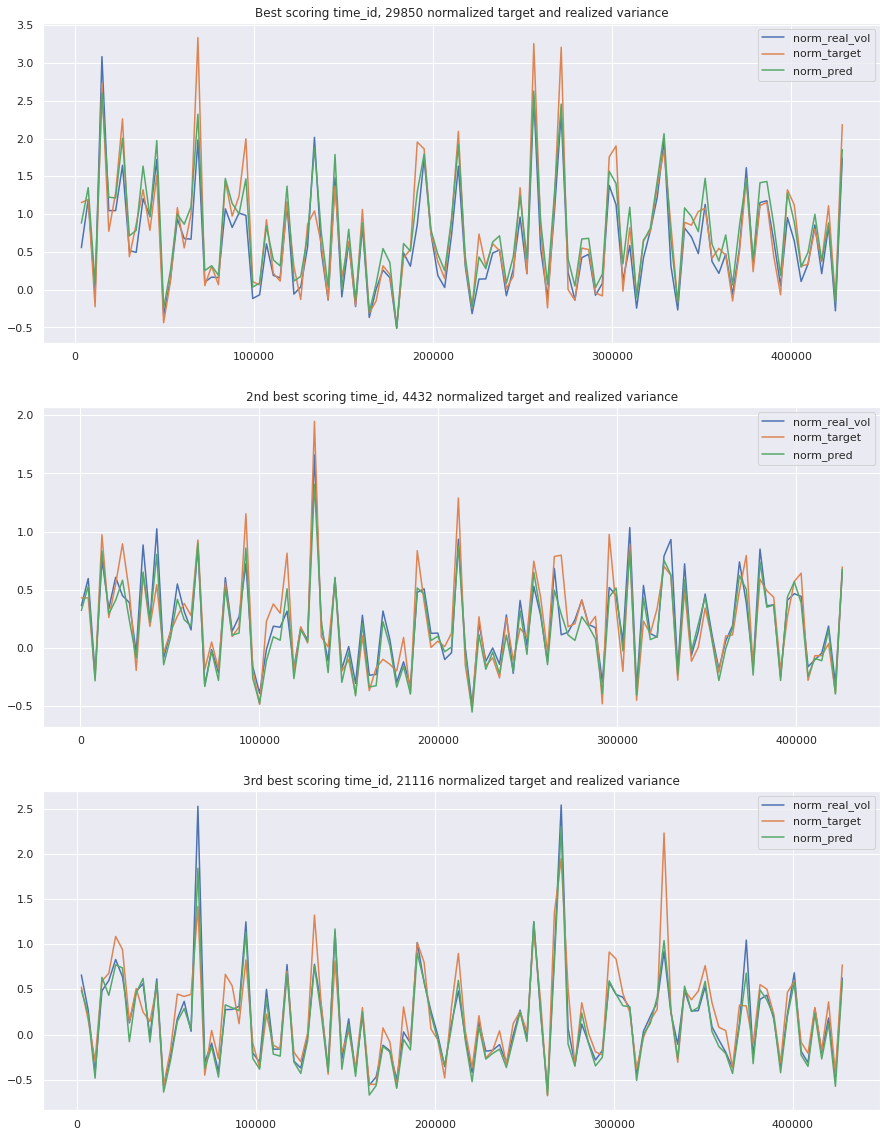
fig, axes = plt.subplots(3, 1, figsize=(15, 20))train[train.time_id ==29850][['norm_real_vol', 'norm_target', 'norm_pred']].plot(ax=axes[0])axes[0].set_title('Best scoring time_id, 29850 normalized target and realized variance')train[train.time_id ==4432][['norm_real_vol', 'norm_target', 'norm_pred']].plot(ax=axes[1])axes[1].set_title('2nd best scoring time_id, 4432 normalized target and realized variance')train[train.time_id ==21116][['norm_real_vol', 'norm_target', 'norm_pred']].plot(ax=axes[2])axes[2].set_title('3rd best scoring time_id, 21116 normalized target and realized variance')plt.show()
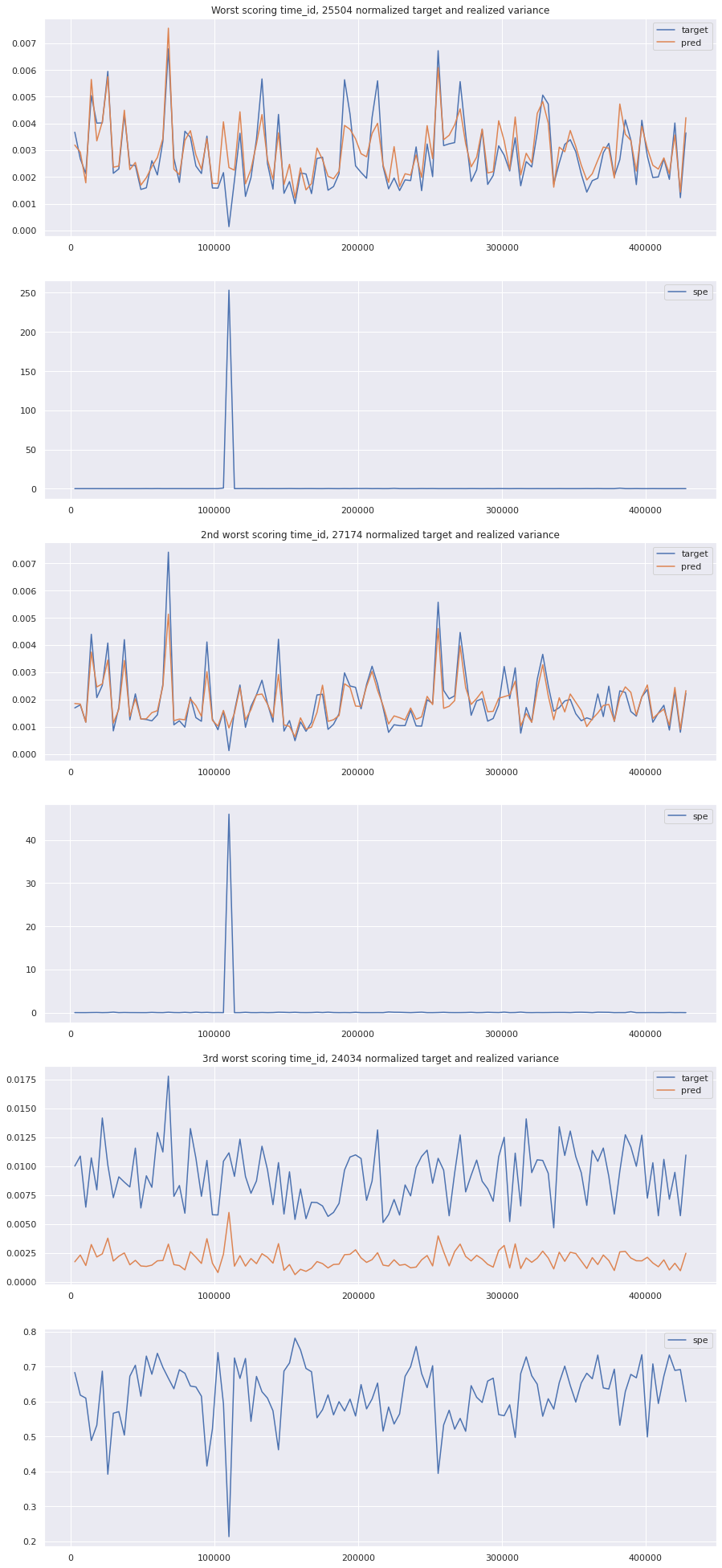
I am still confused about the third worst time_id. It looks like the predictions follow the first 10 minute volatility, and should be far off. Maybe I am missing something by normalizing. Lets just look at the raw values of preds and the target, along with the error plotted underneath for reference.
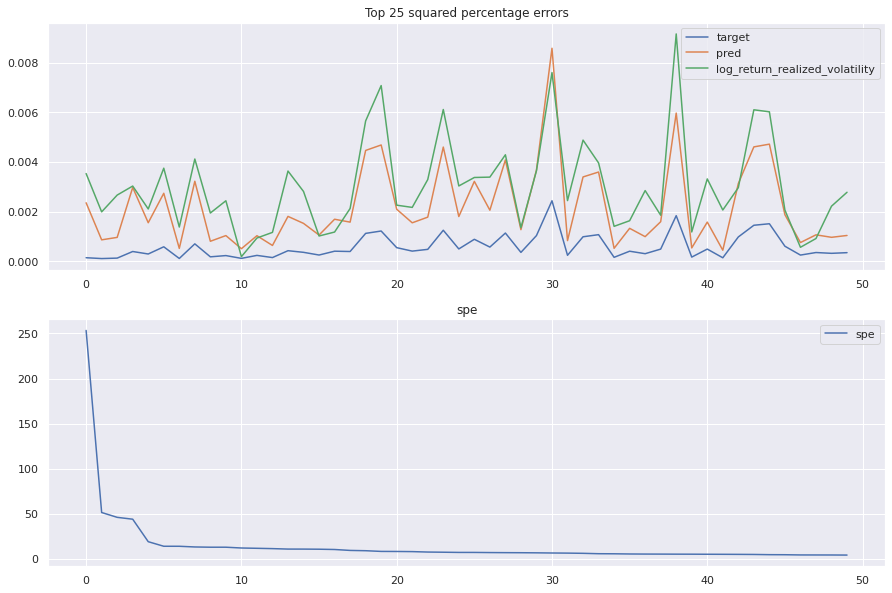
Plot that finally brings some understanding of the large errors
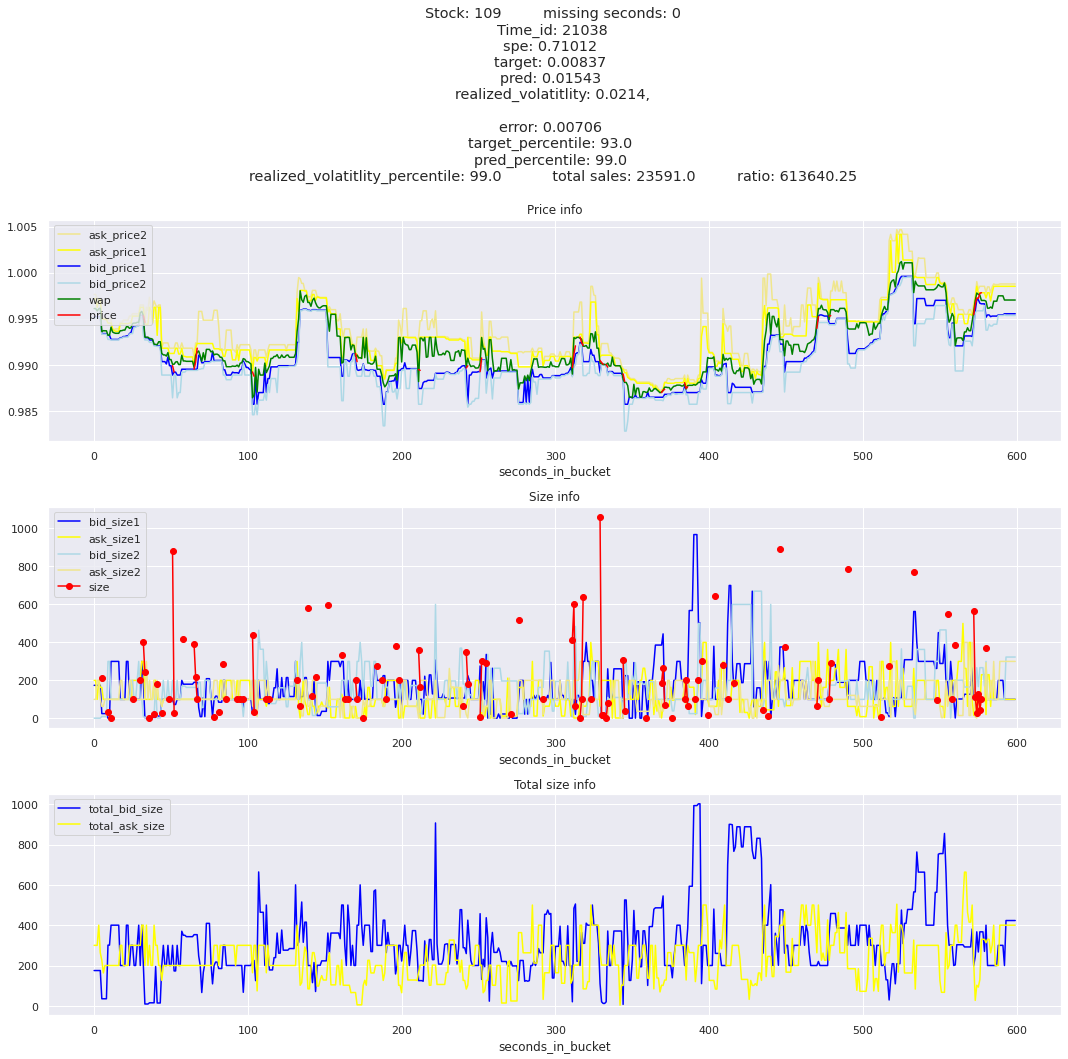
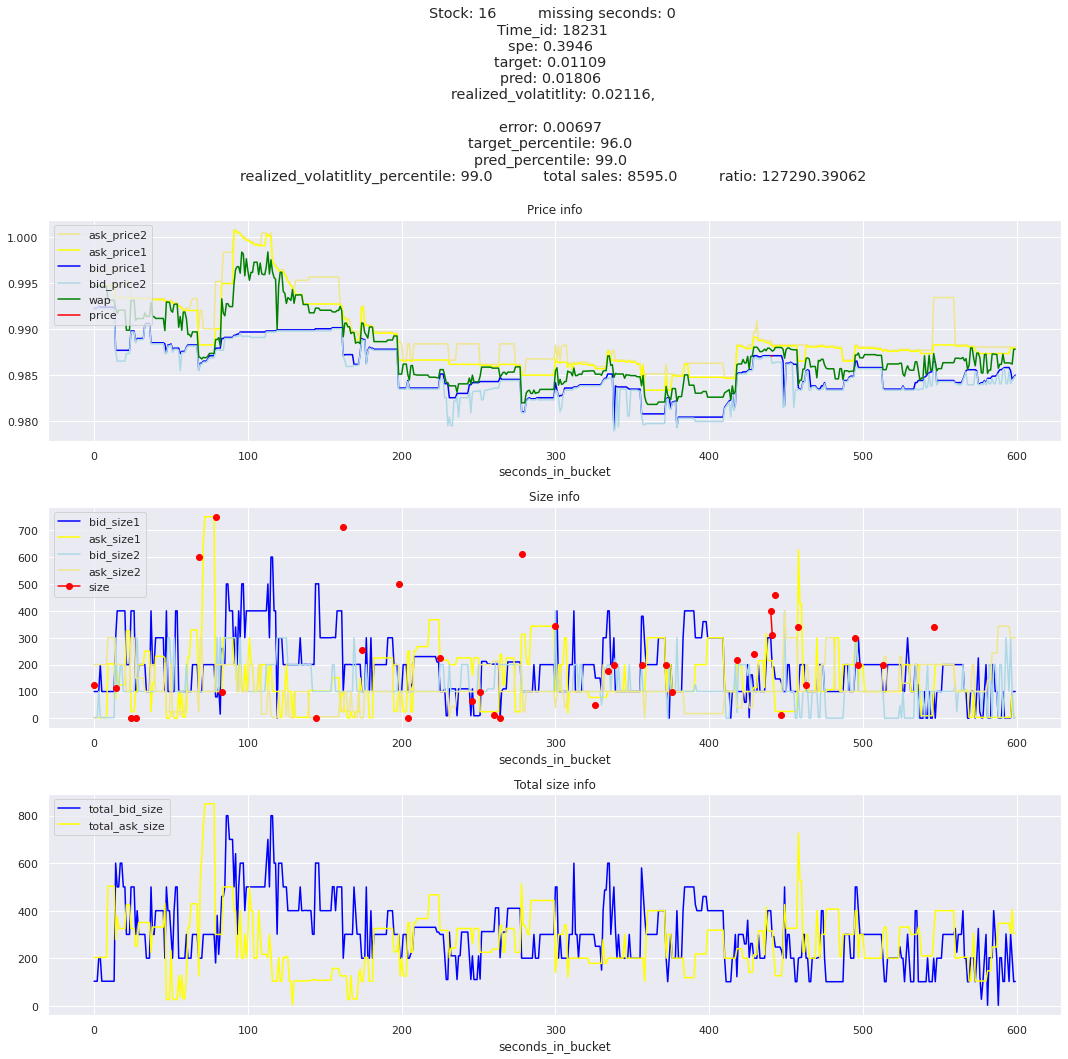
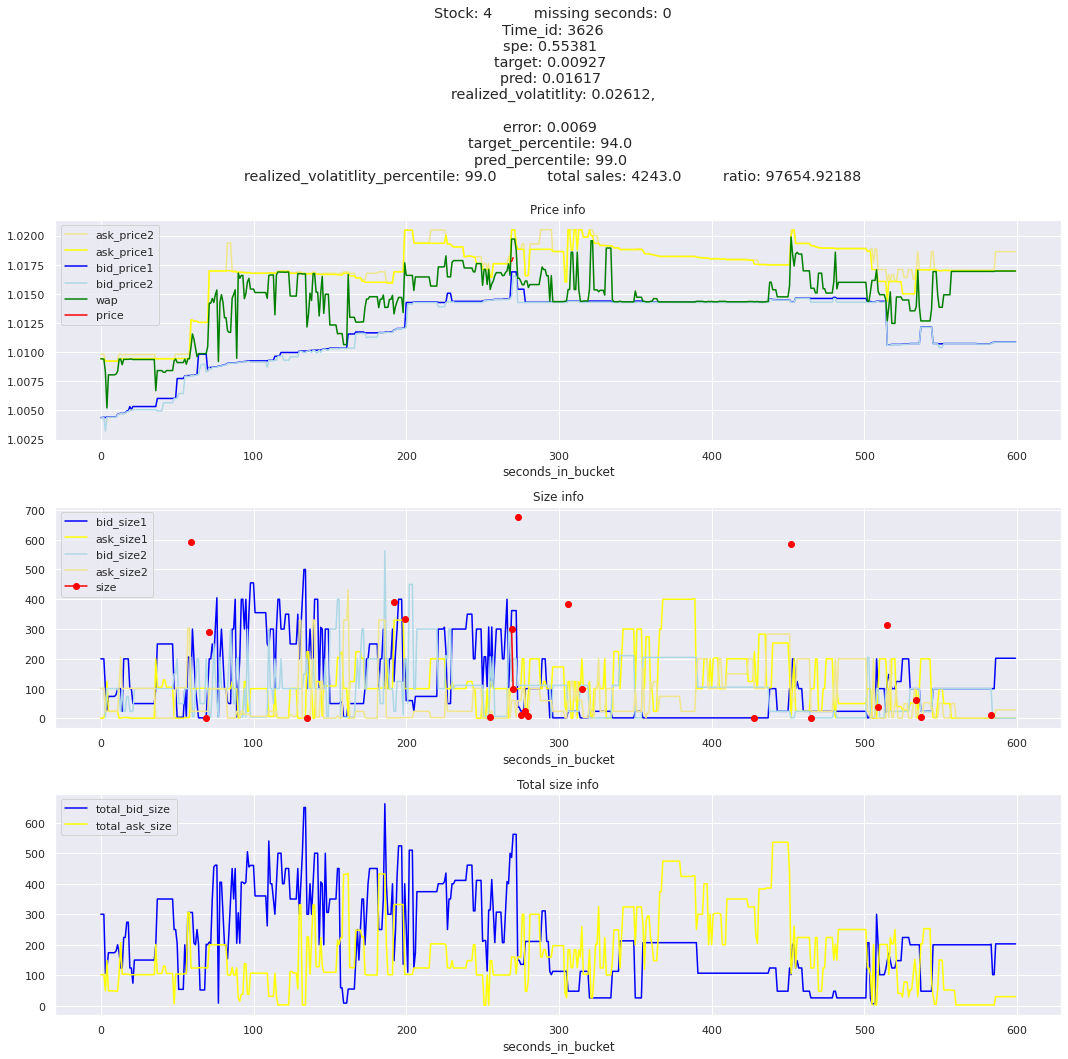
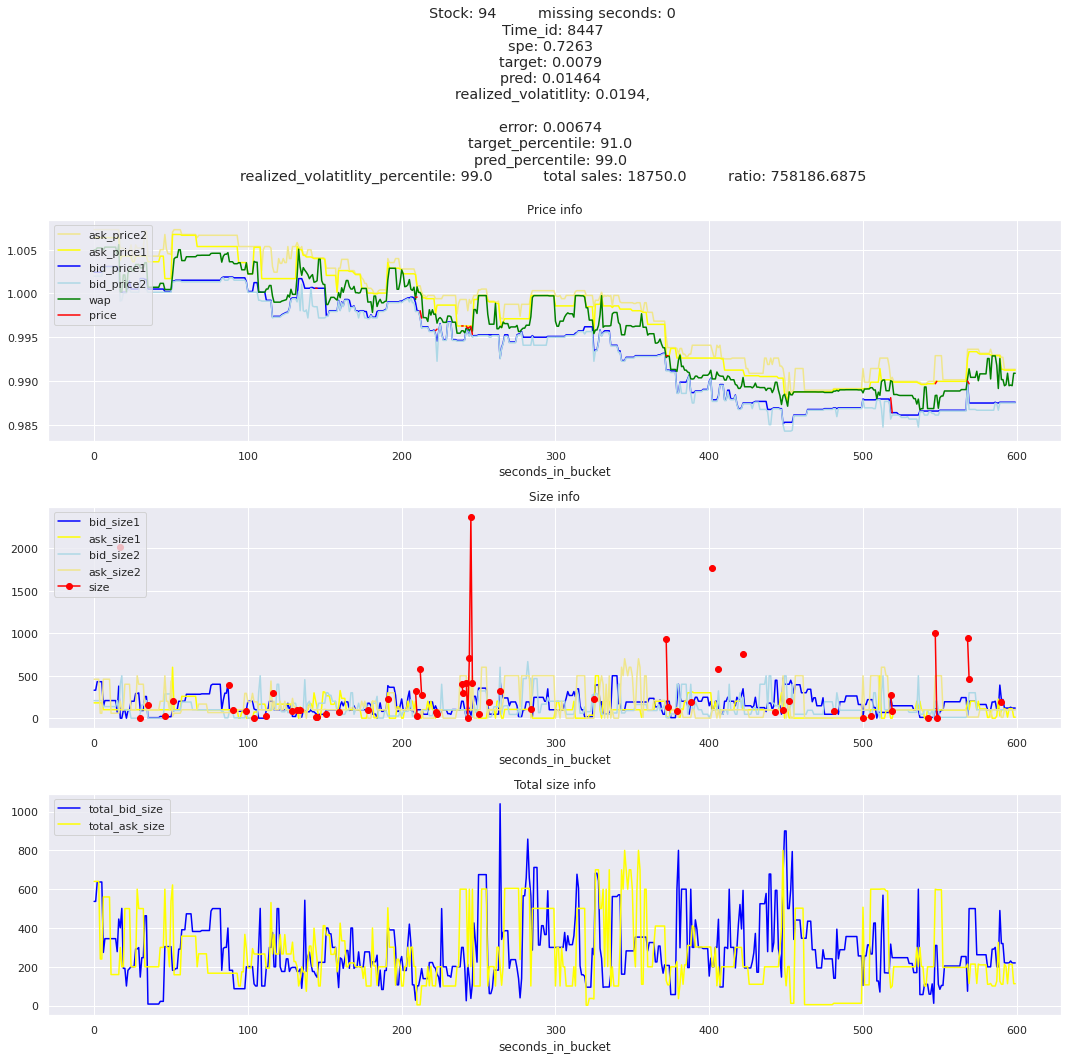
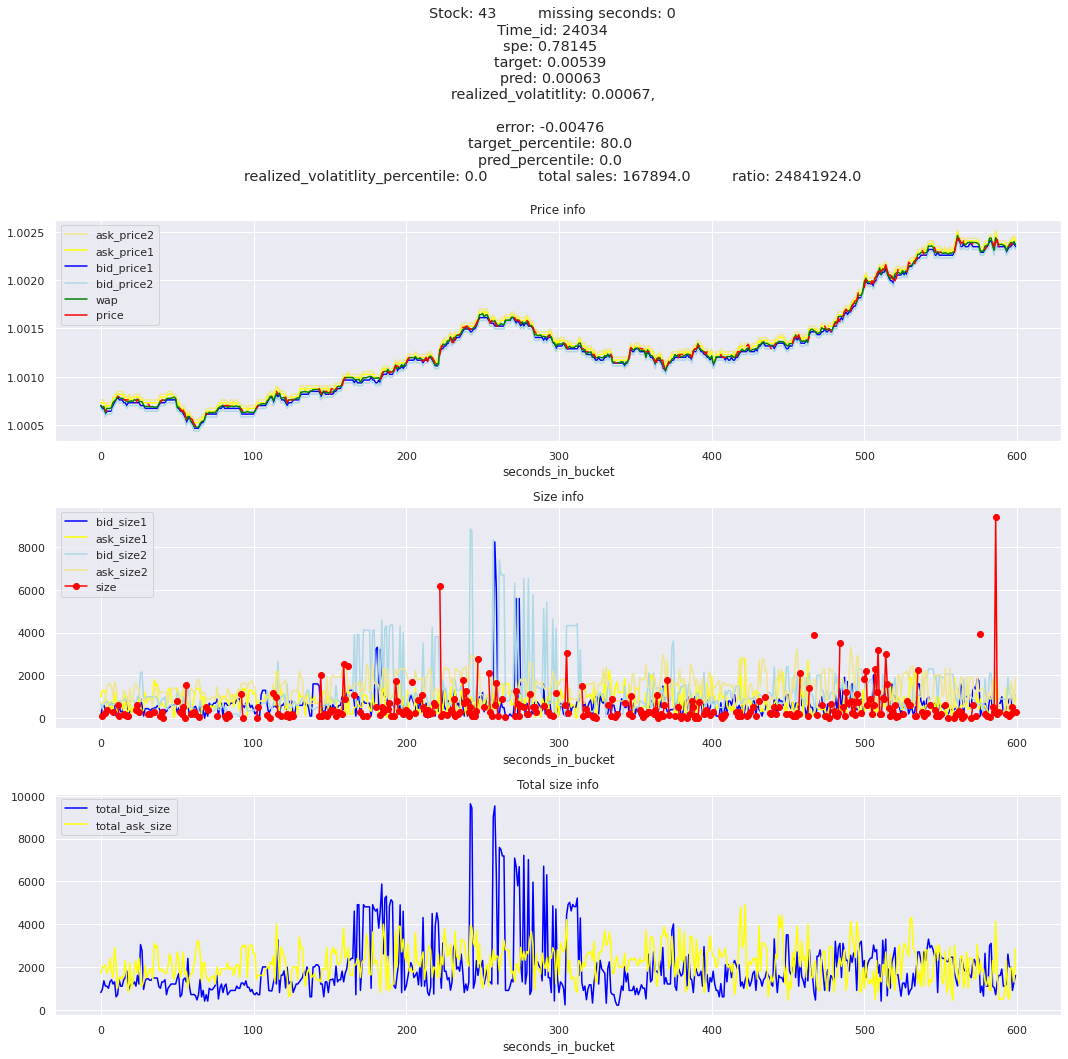
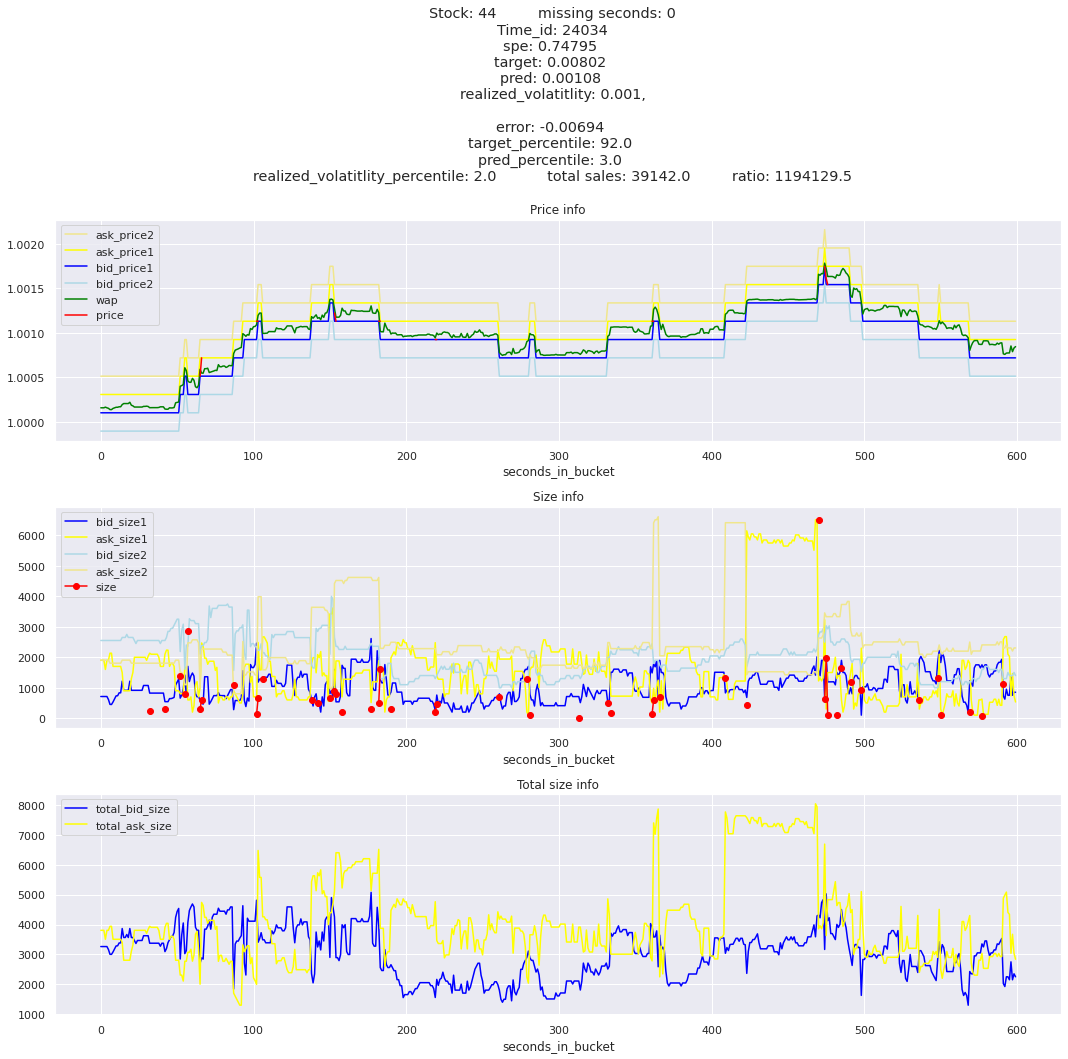
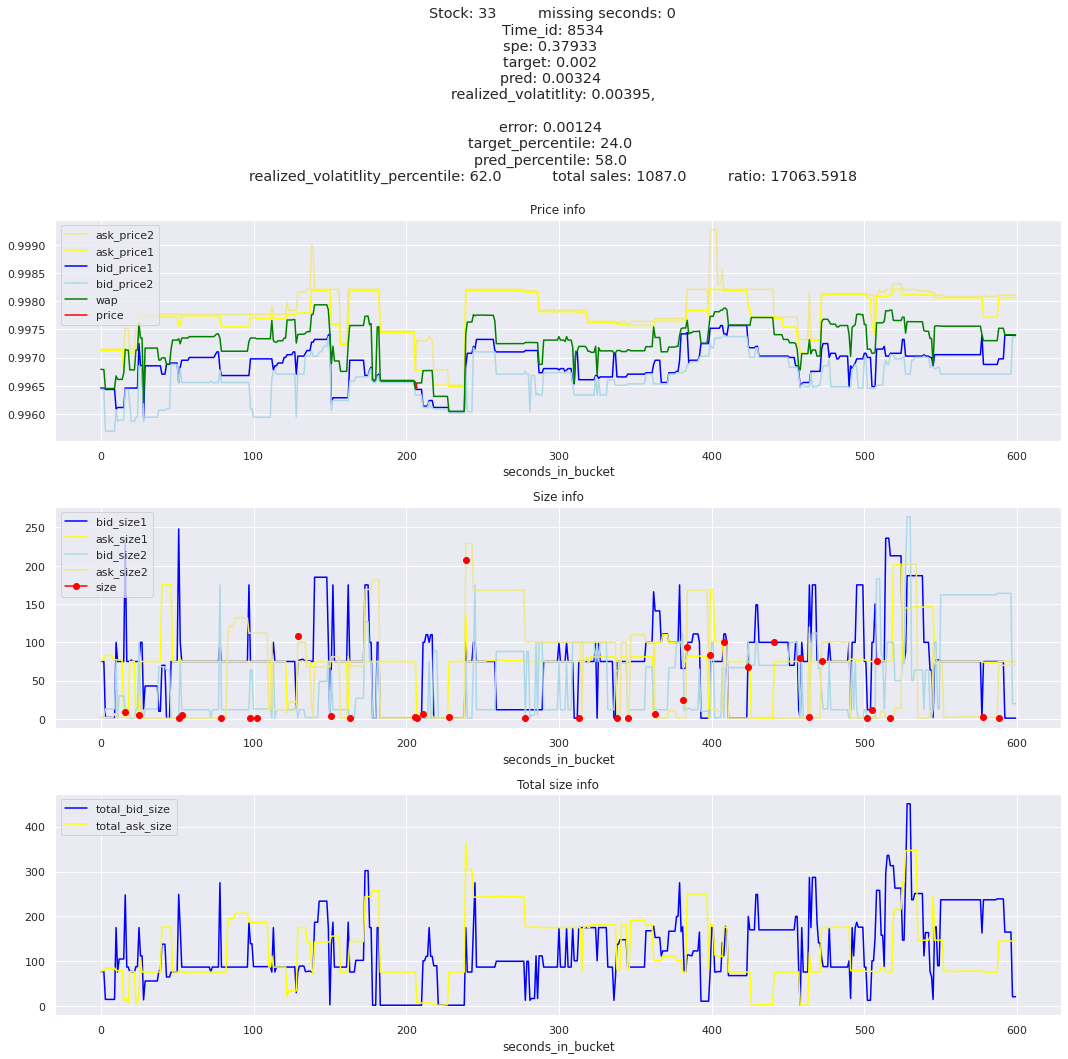
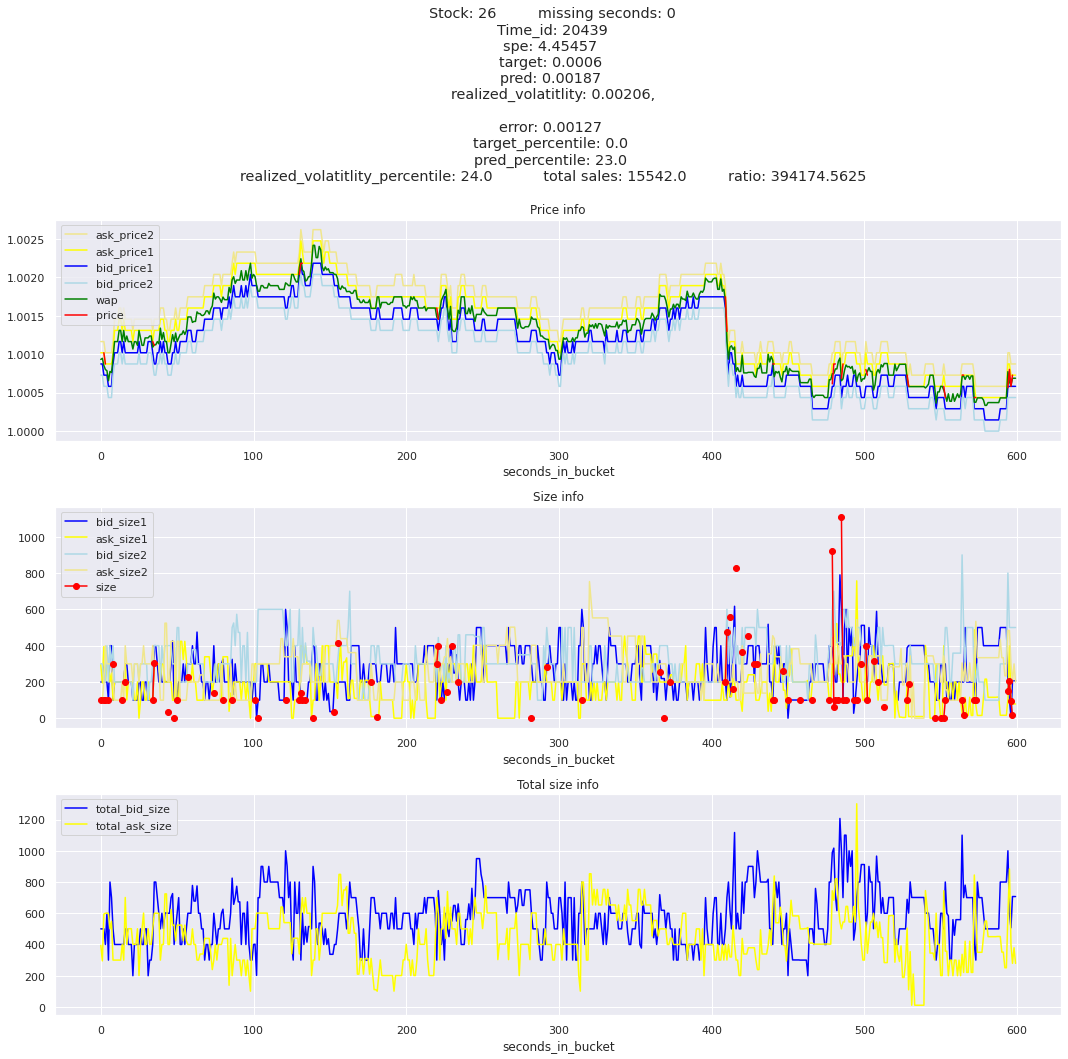
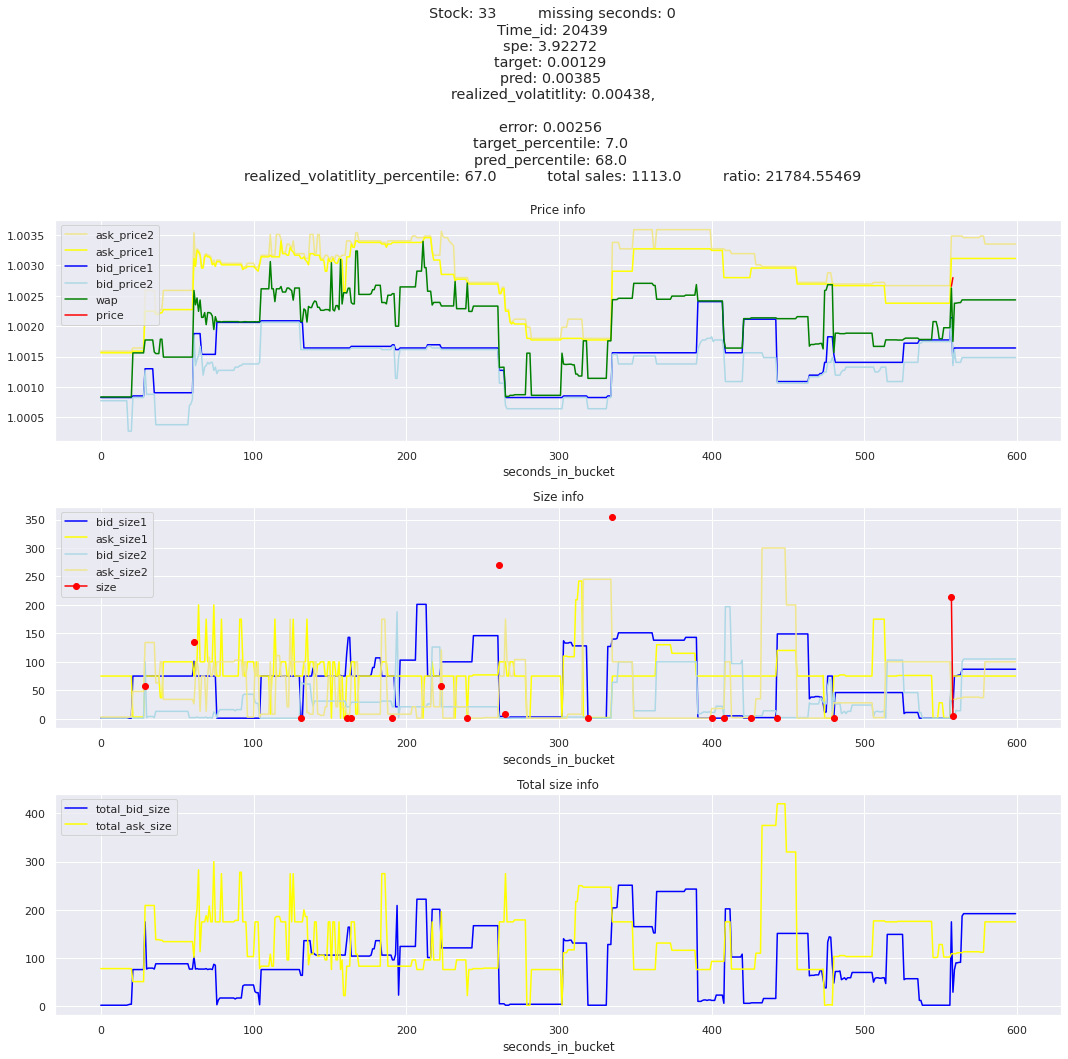
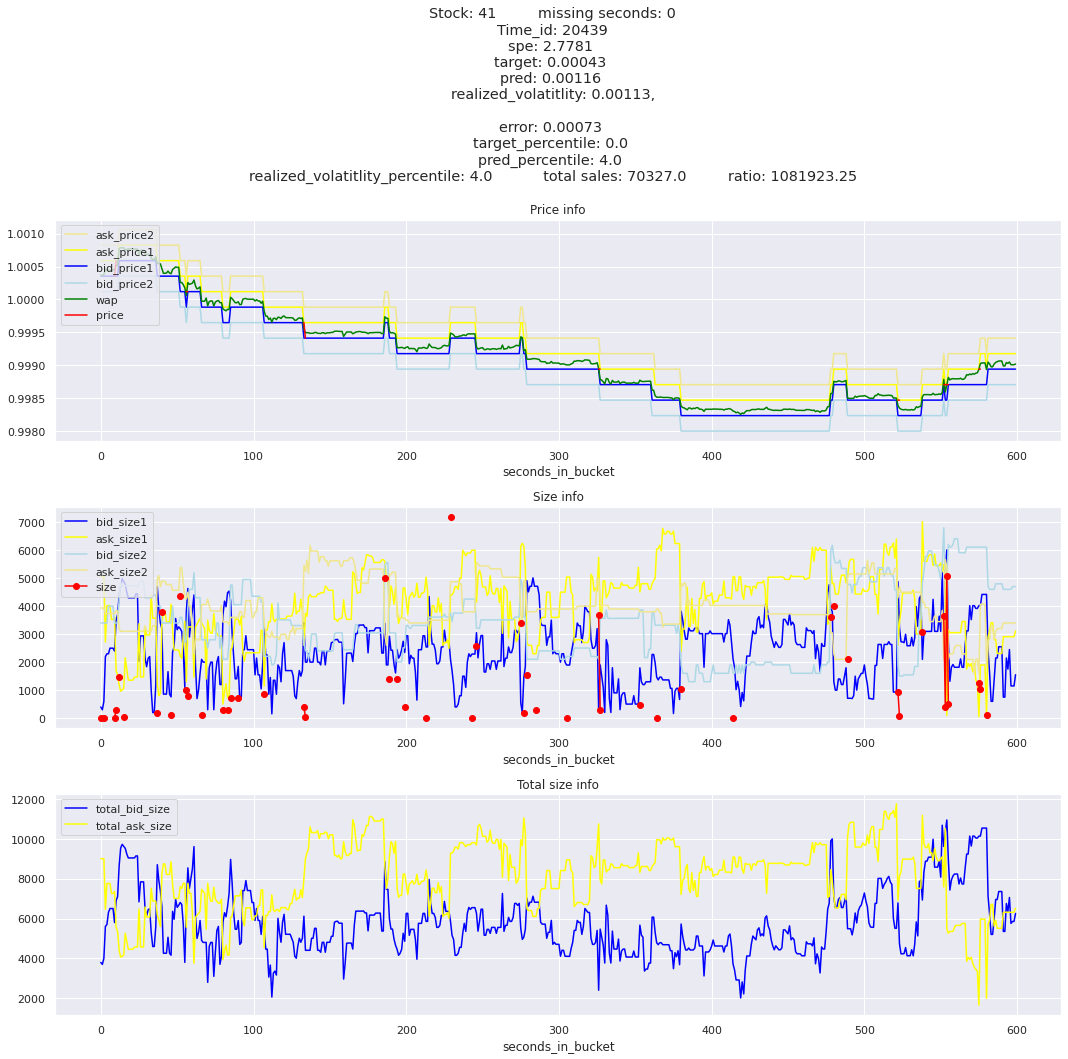
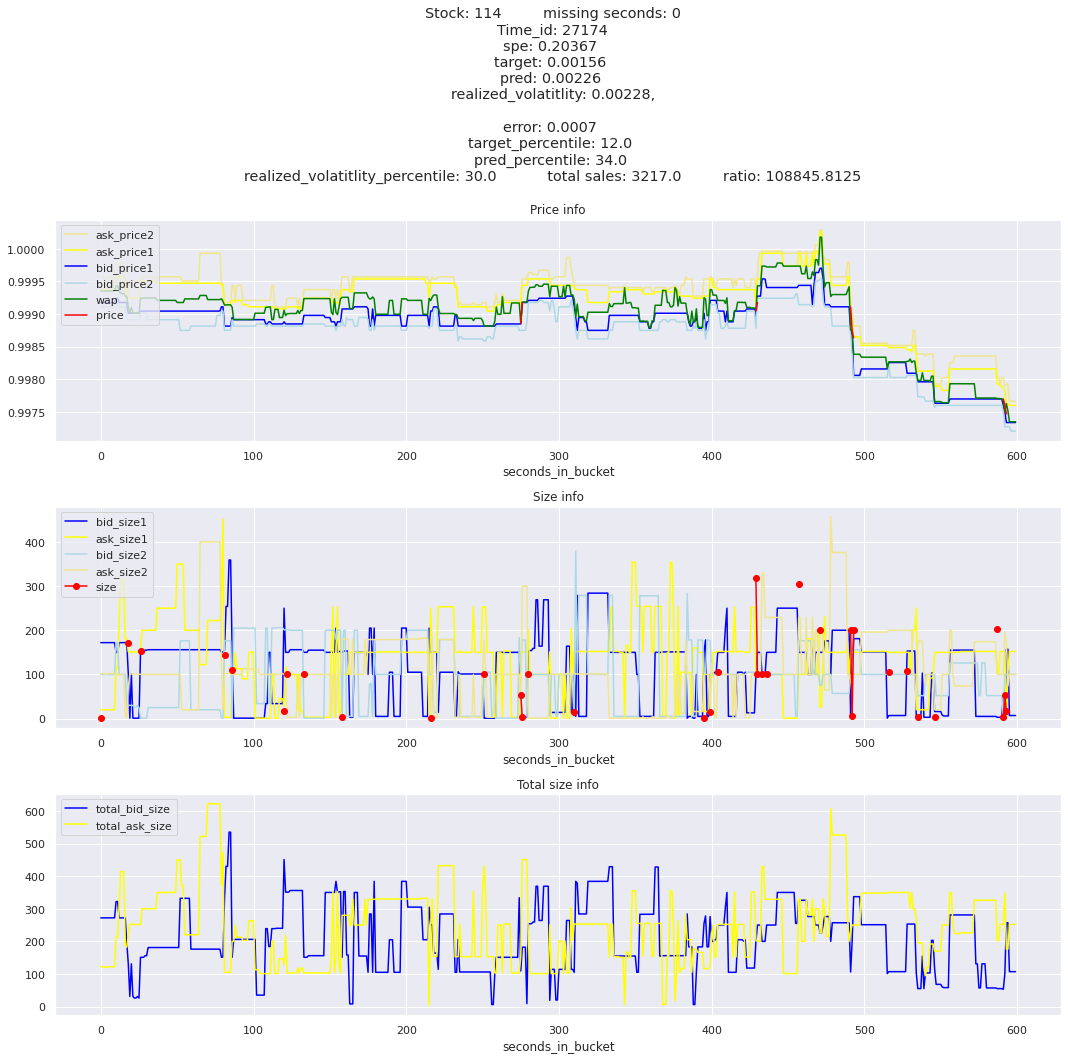
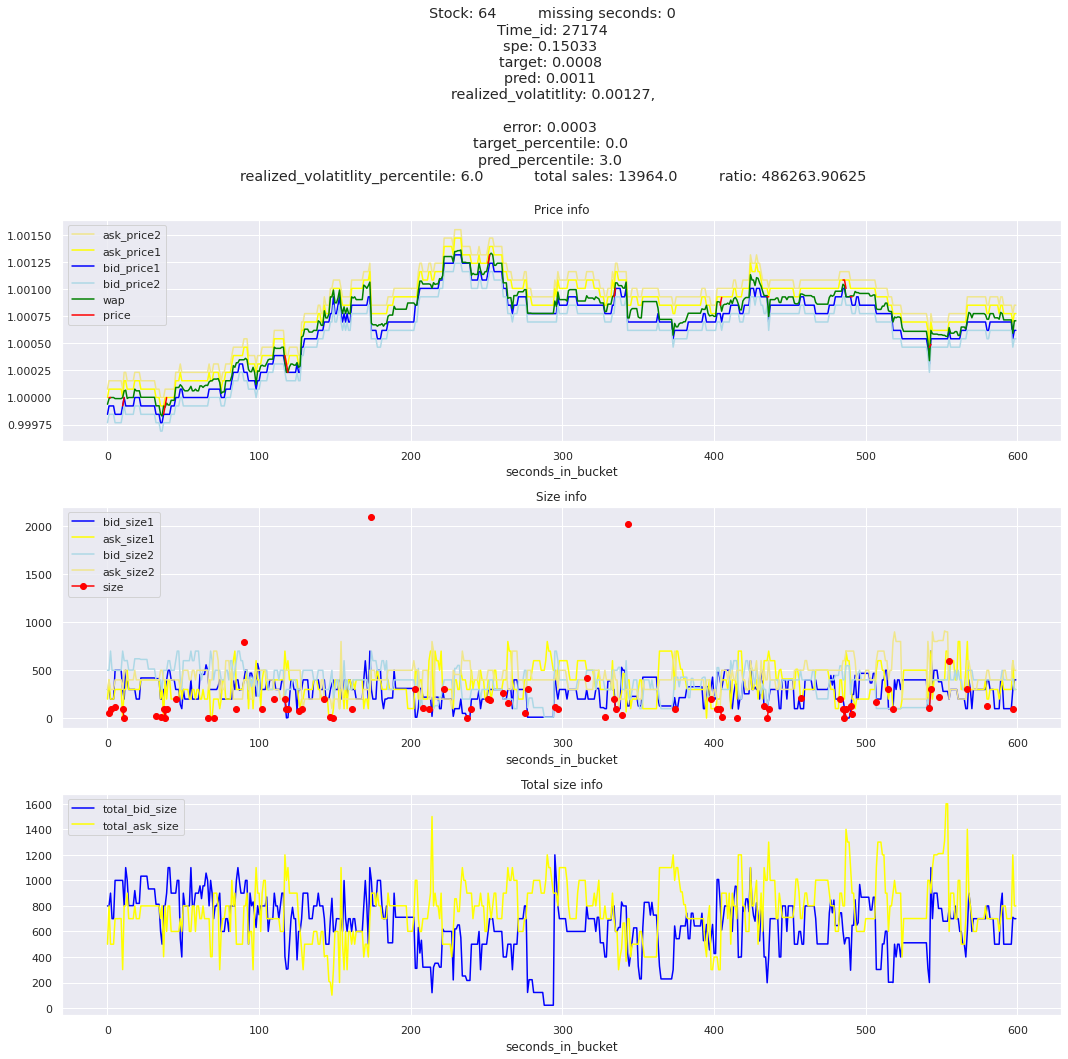
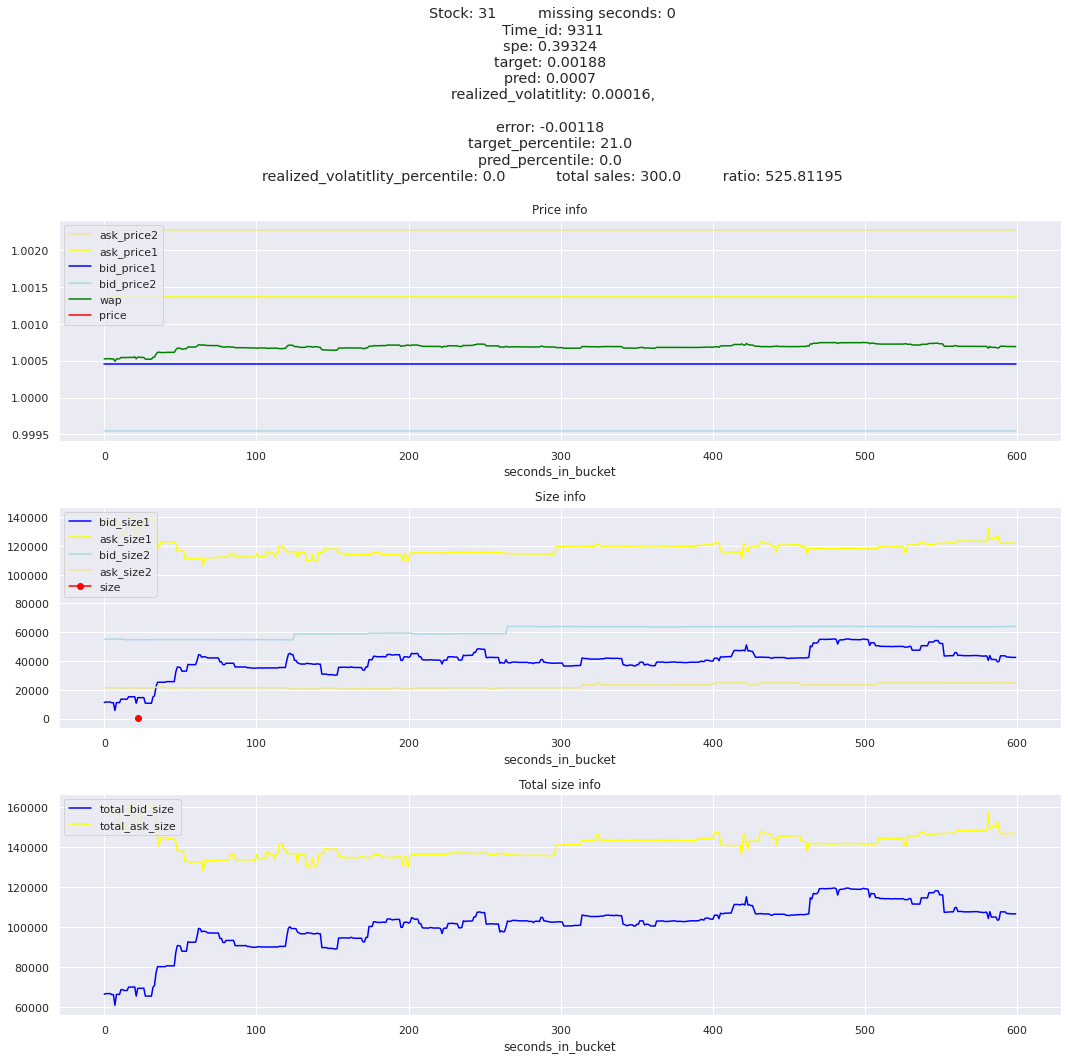
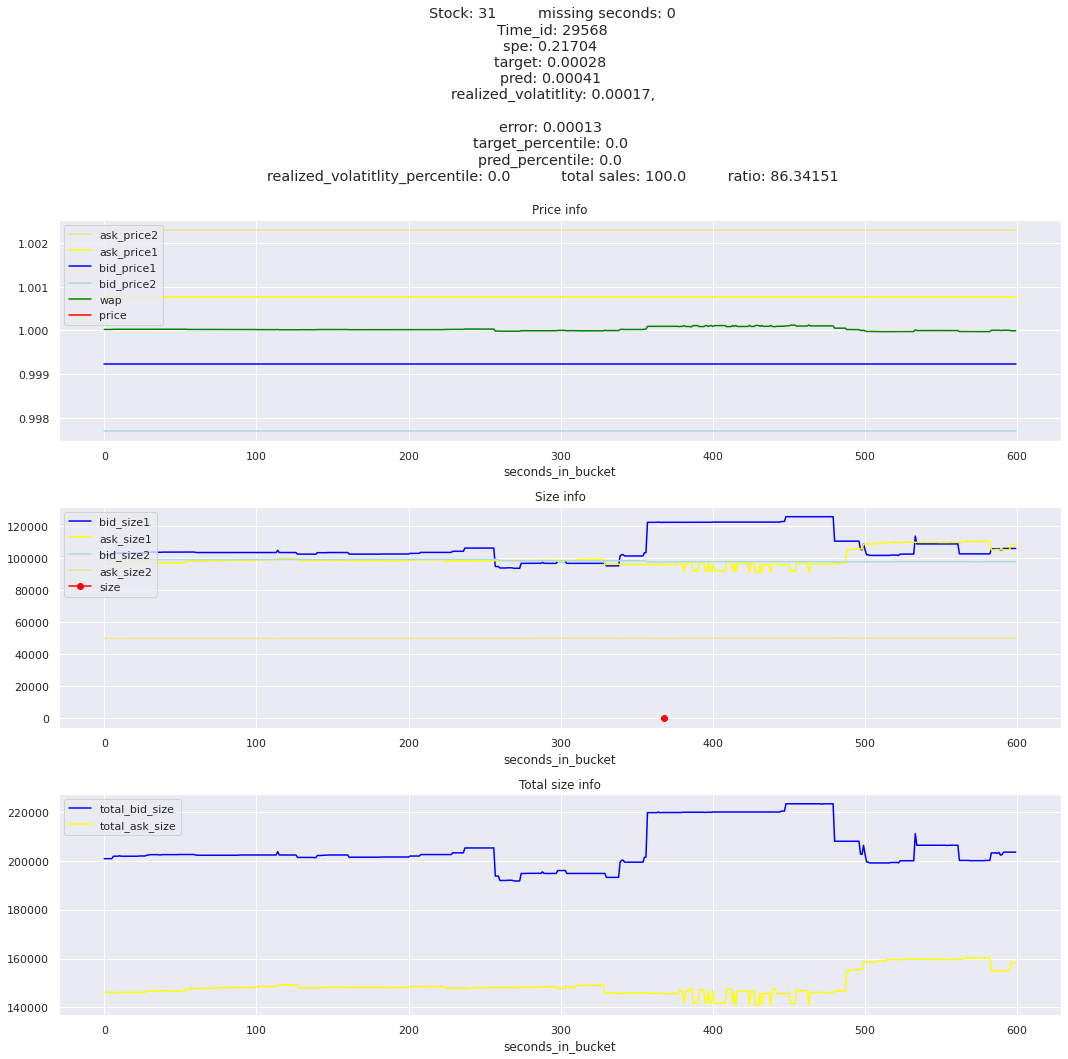
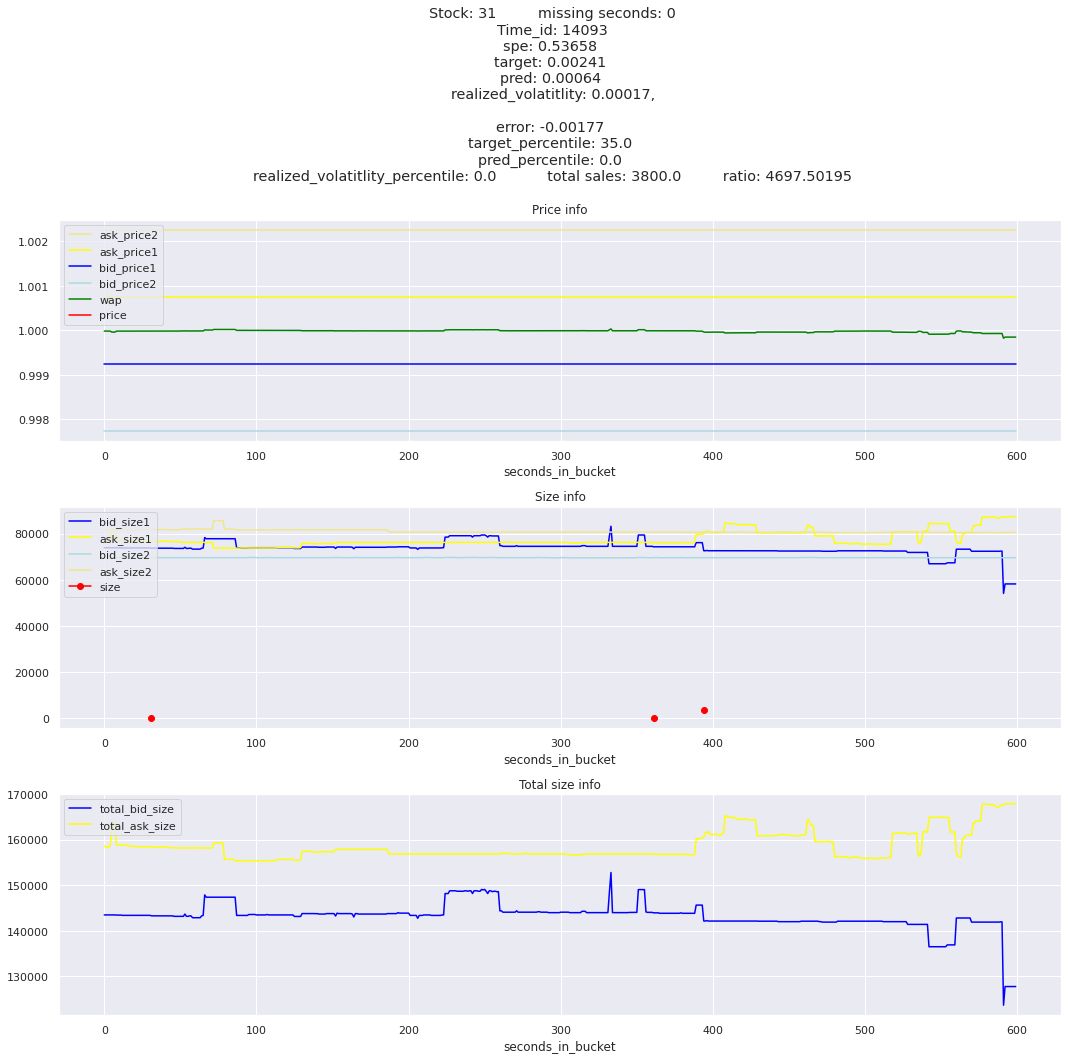
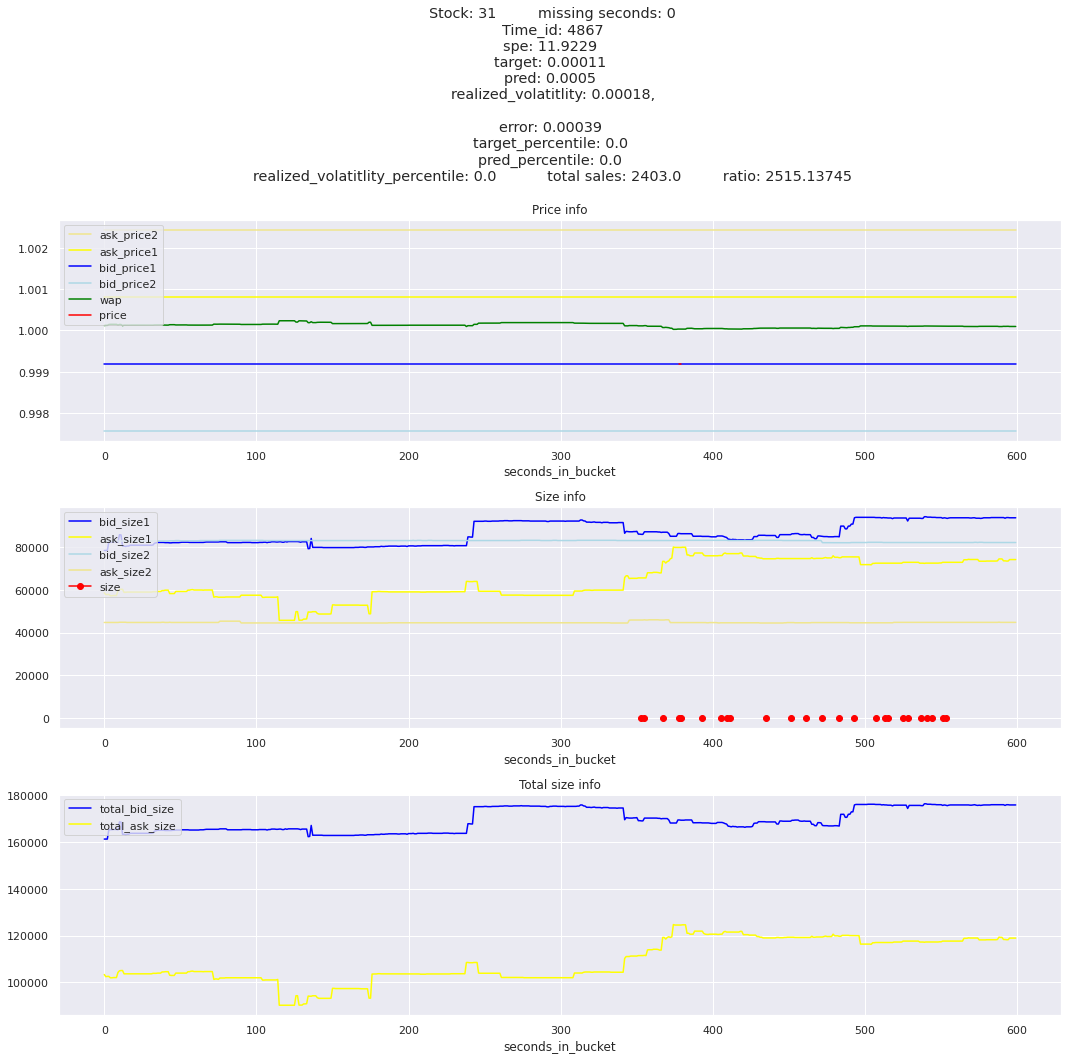
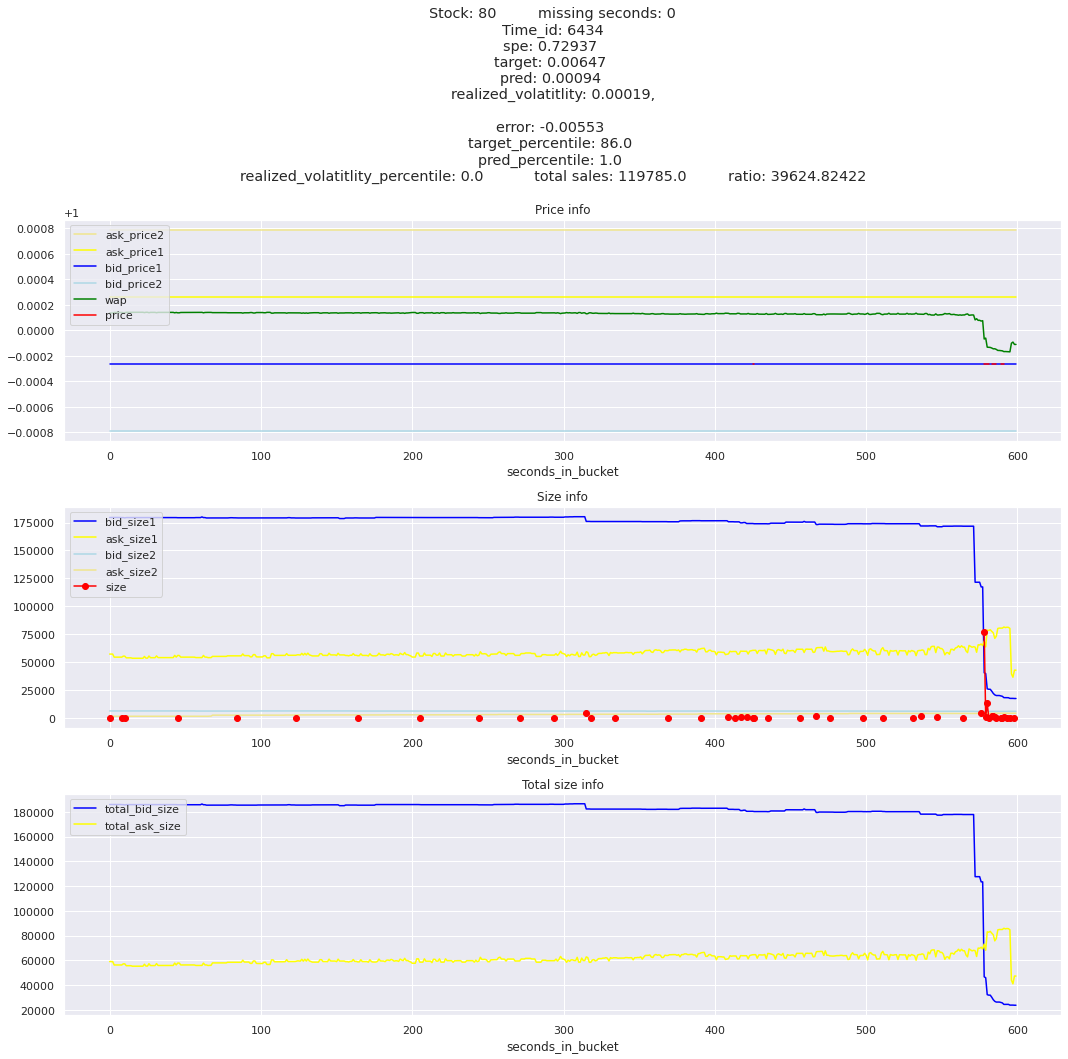
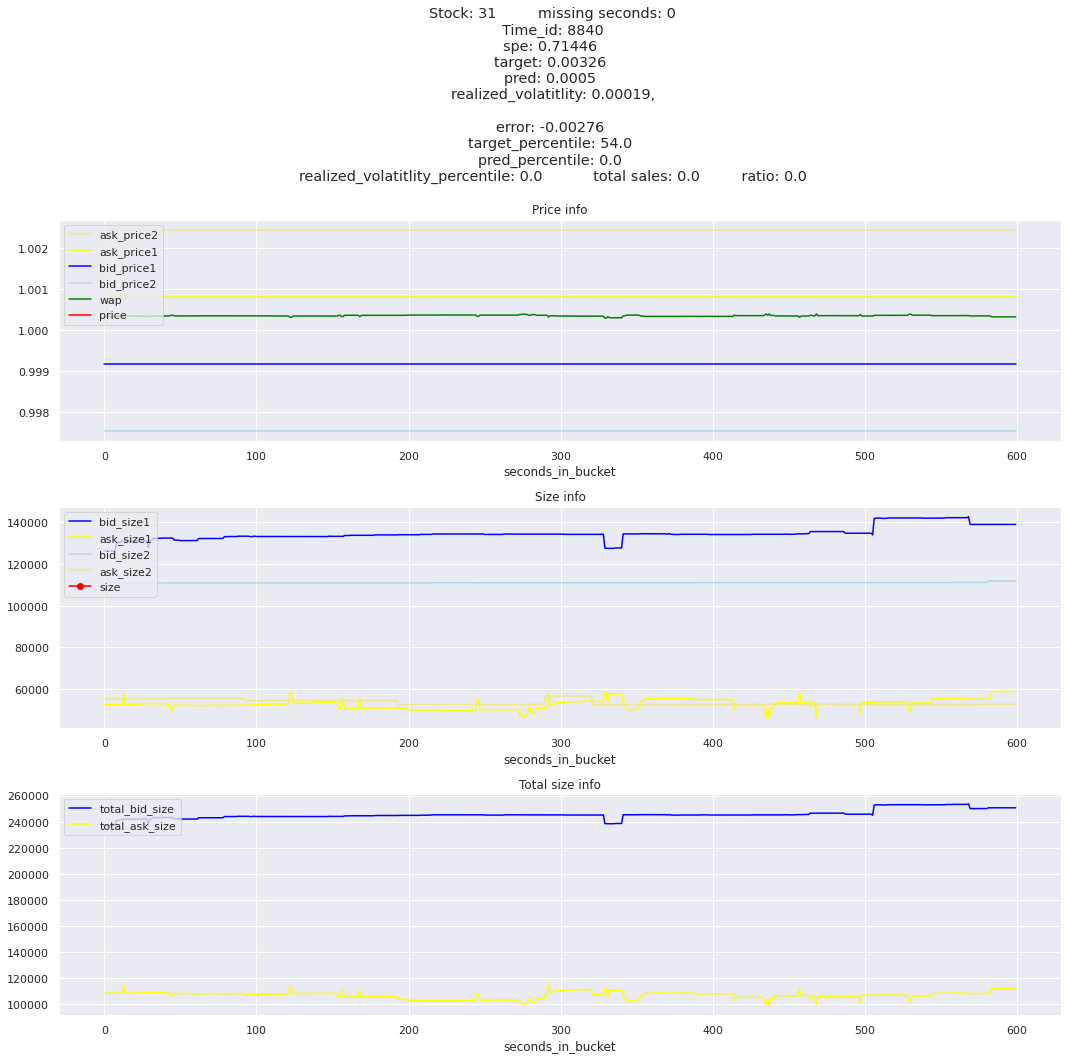
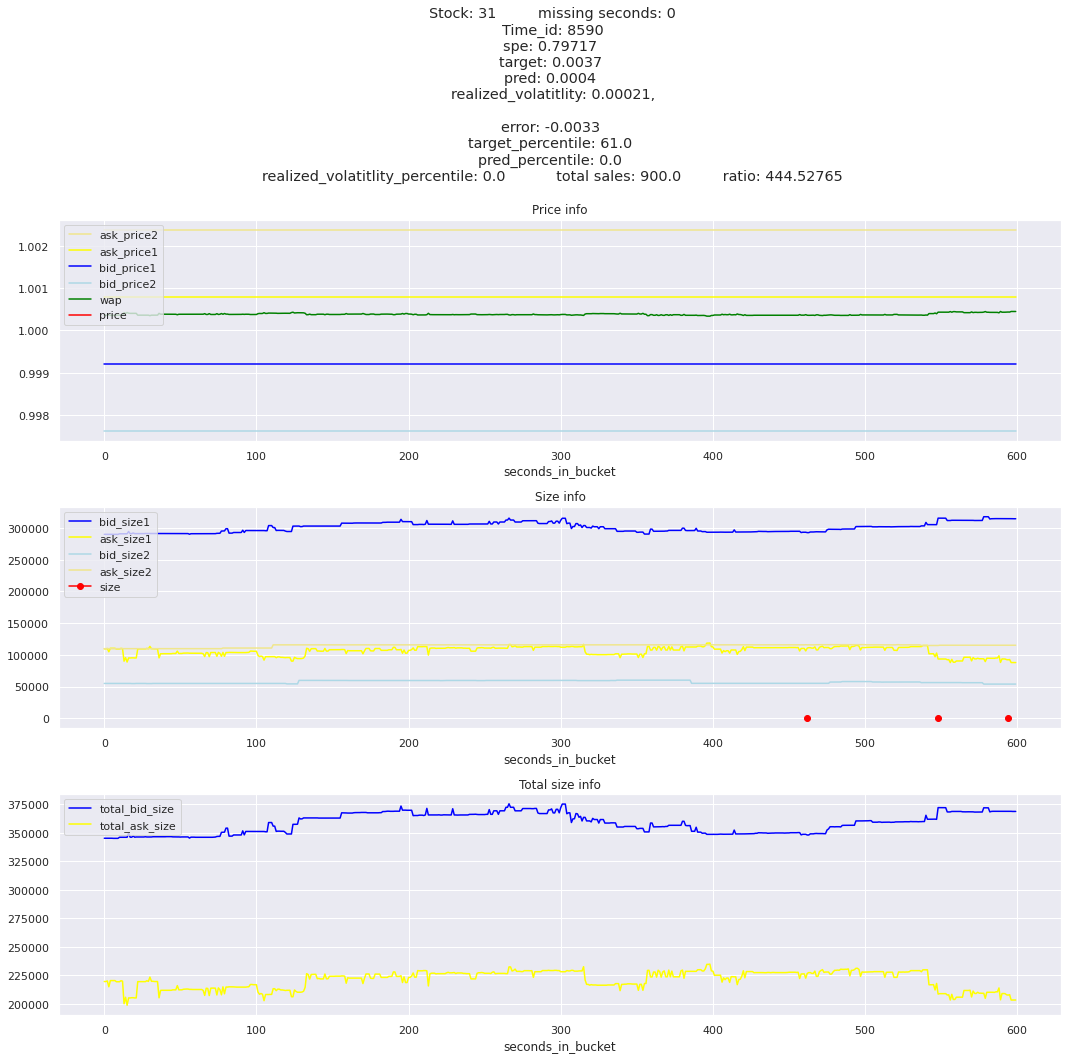
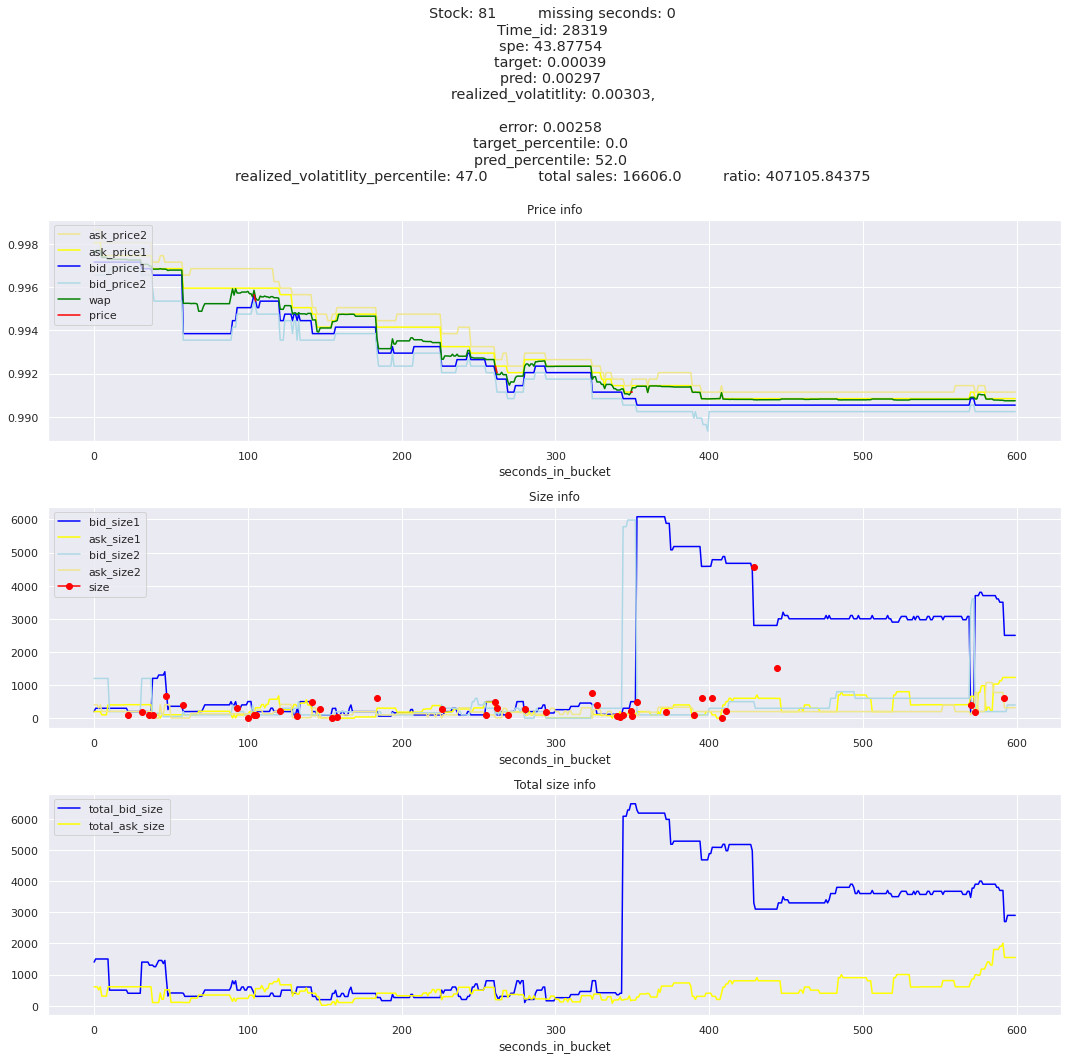
key takeaway: the largest errors are caused when the target is small because the errors are divided by the target in the metric calculation. The top two worst scoring time_ids both have a single prediction with an extremely low target, while the 3rd worst time_id has a generally low target for all stocks.
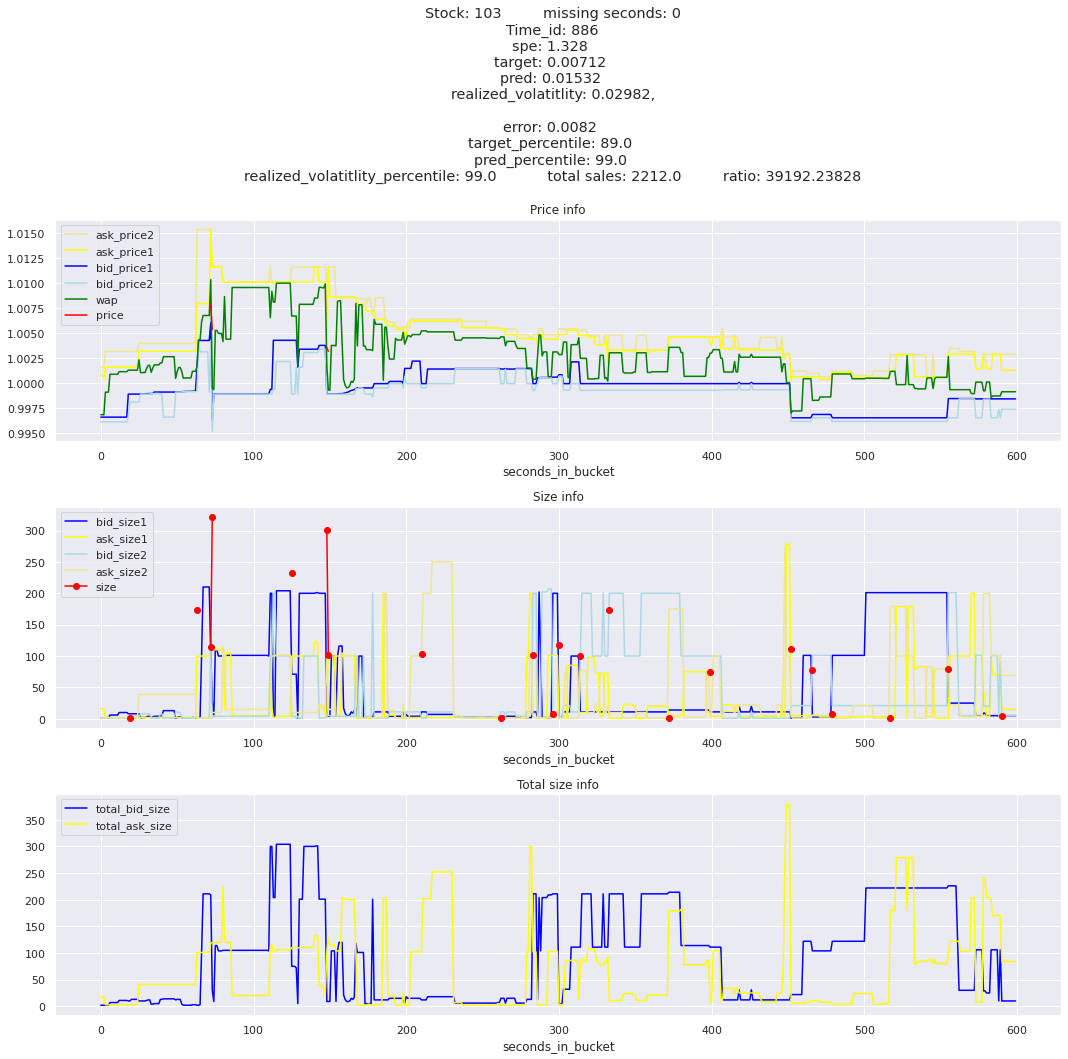
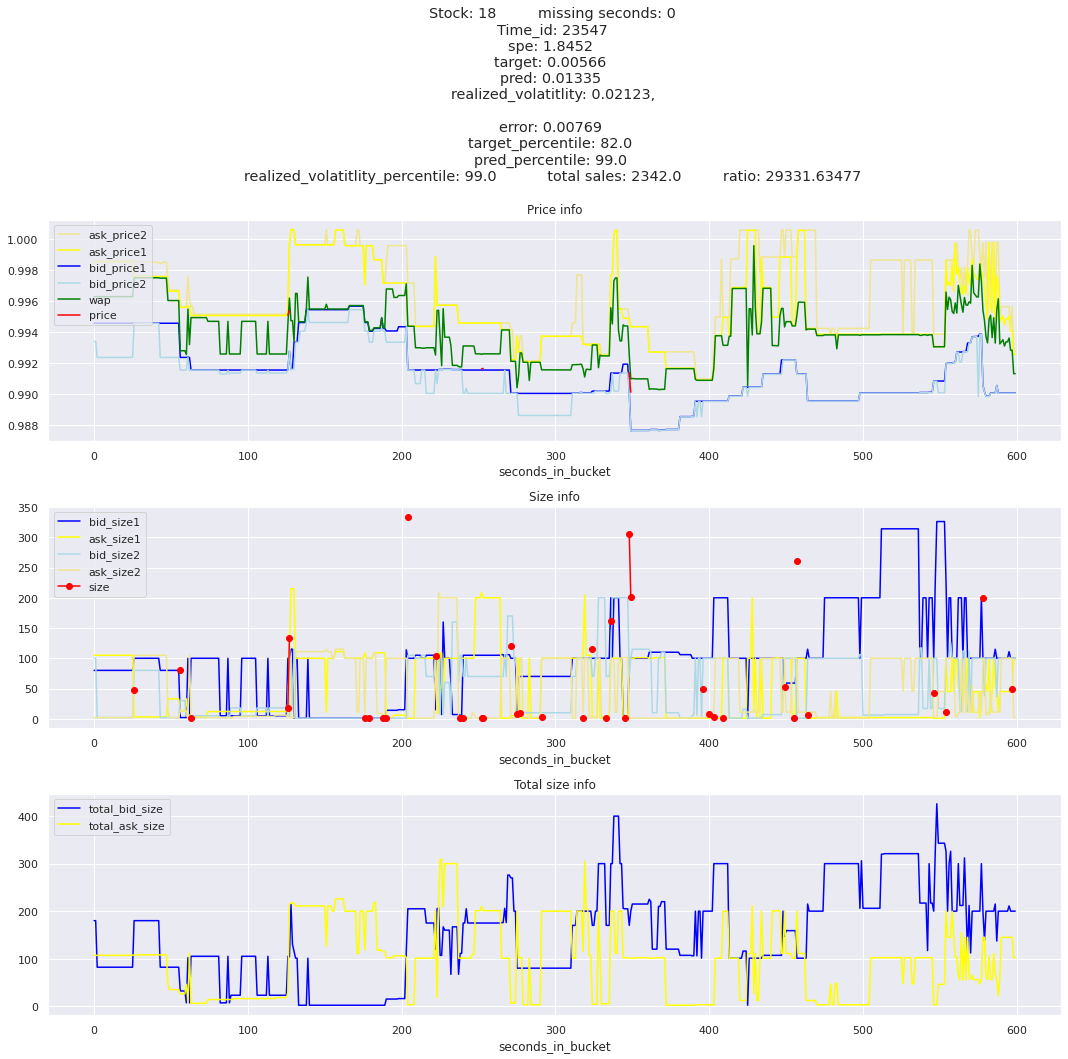
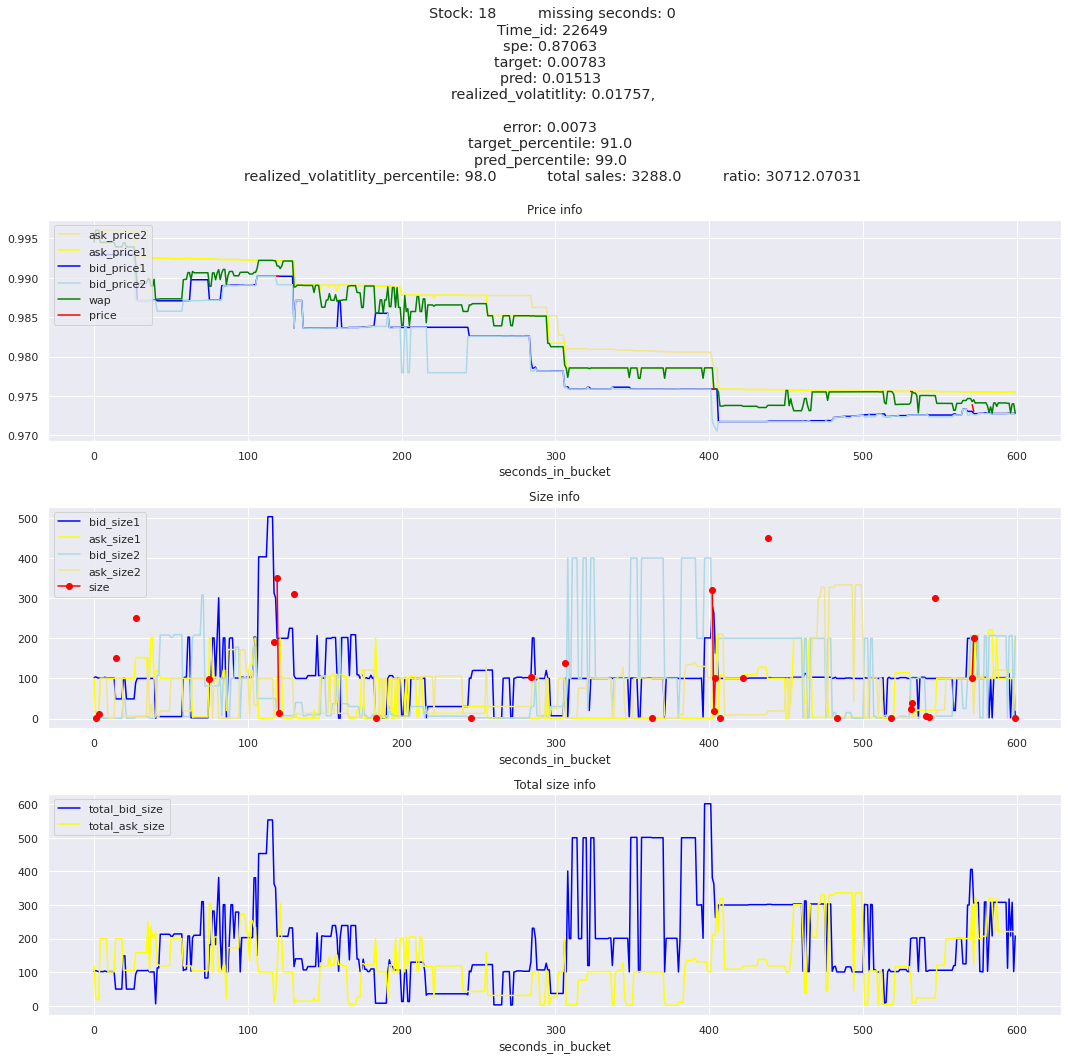
Looking at rows with the highest error, testing hypothesis that a small target is the culprit
It definitely seems that the largest errors are coming from overpredicting the target, along with an especially small target. I think overprediction could be the only times when we have a large penalty from the metric. Lets look at the largest losses where we underpredict.
The largest spe is less than .92. For reference, if we predicted 0 for all targets our average spe and overall metric would be 1. Given that the underpredicted errors gave spe penalties in the 5,6, and 7 range at the high end (highest about 200) with relatively small absolute error, and these underpredictions give a max penalty less than 1, I am certain that overpredicting especially small targets is the largest source of error.
Looking for signals of low volatility
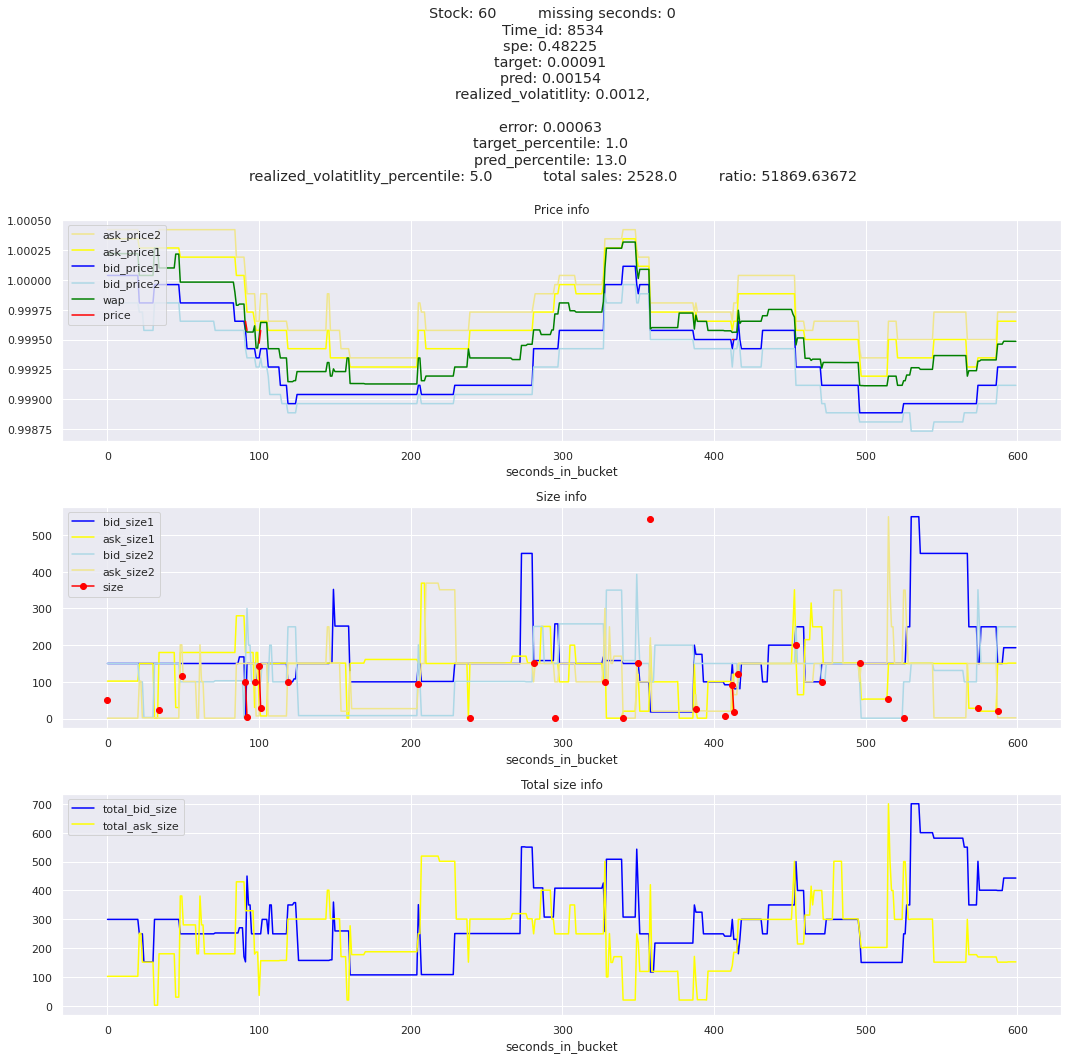
Lets look at some of the book and trade data for the top losses. Maybe we can find some features that show that we are about to enter a low volatility period, even if the previous 10 minutes was high.
def add_percentile(df, col): """Adds `{col}_percentile` to compare where each row ranks in terms of `col`."""iftype(col) ==list: for c in col: df = add_percentile(df, c)else: df[col +'_percentile'] = (df[col].rank(pct=True) *100).astype(int)return df
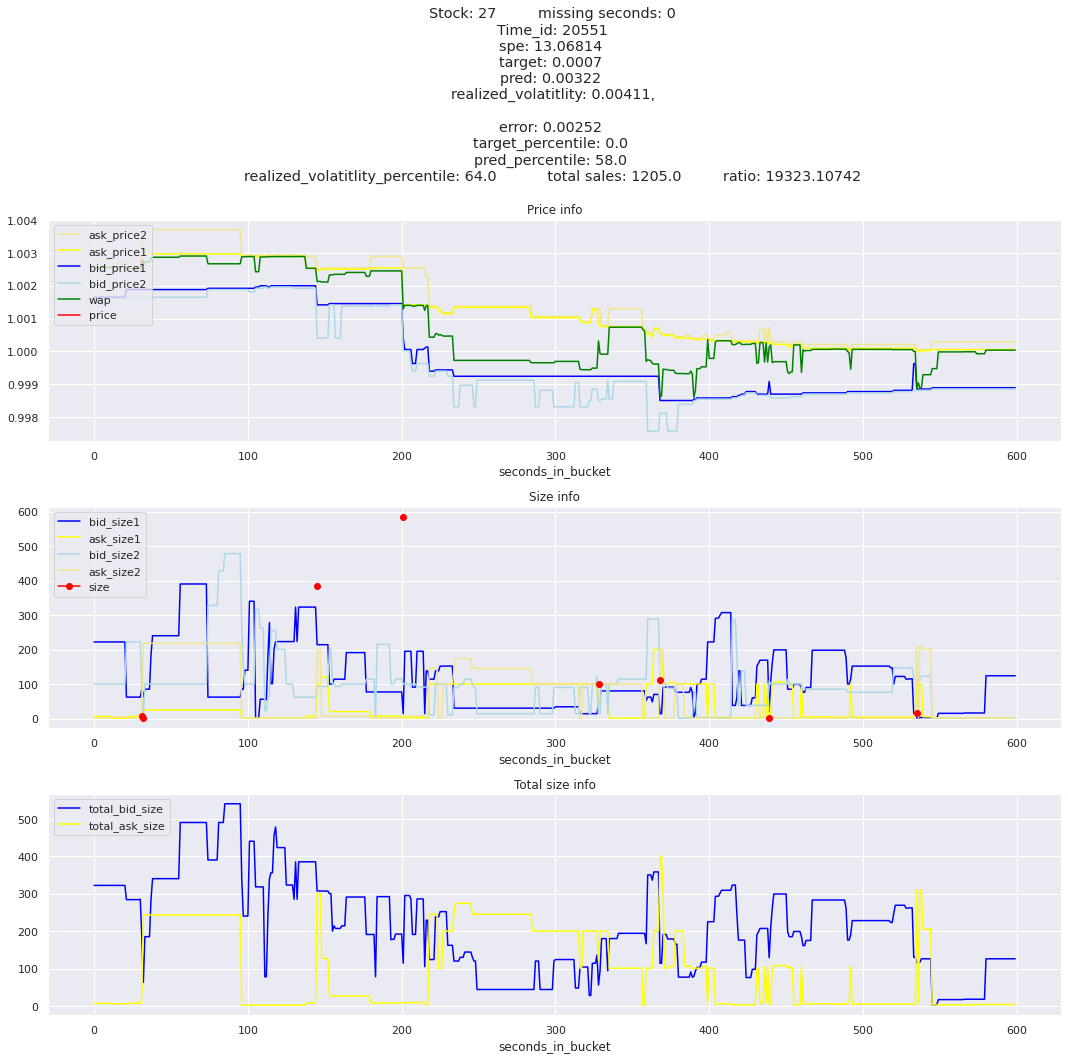
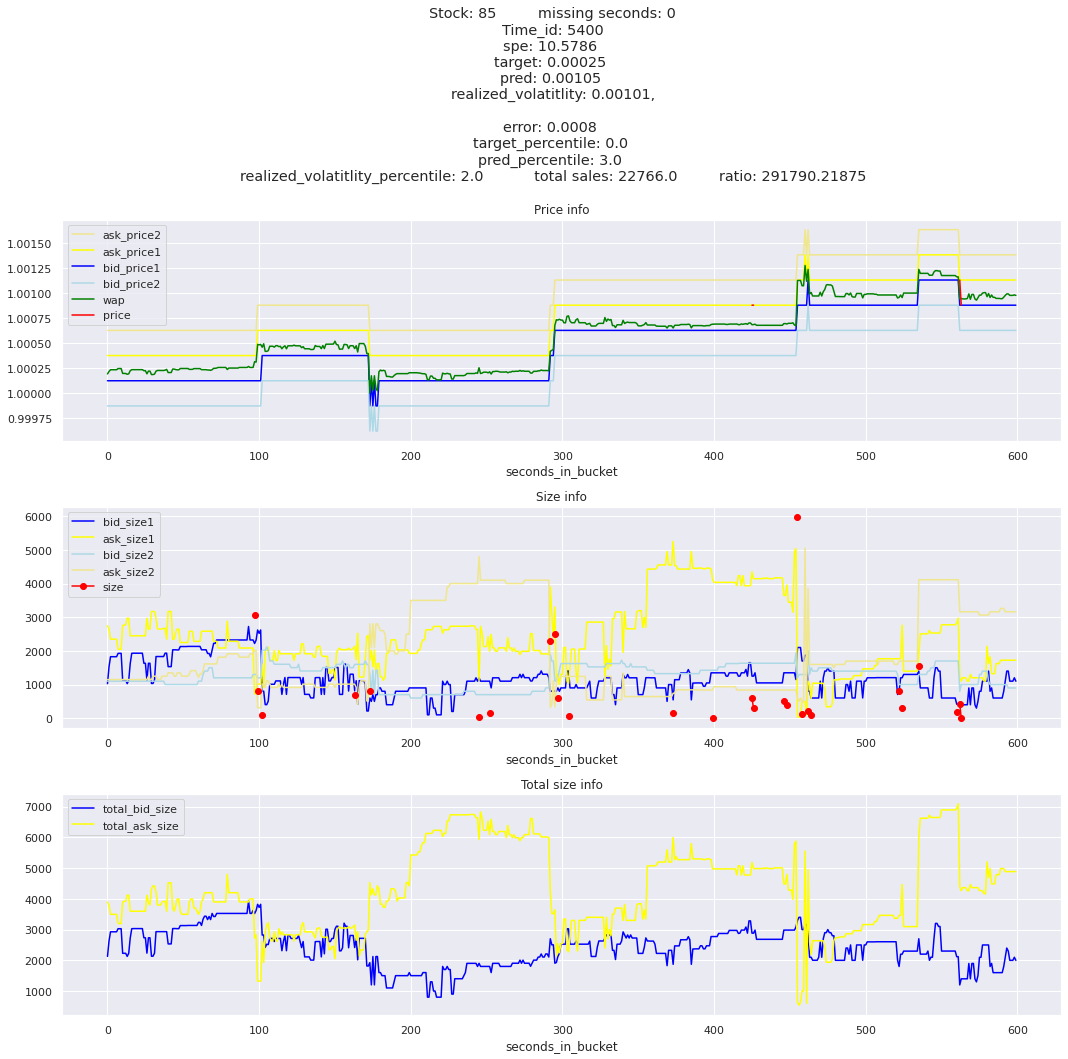
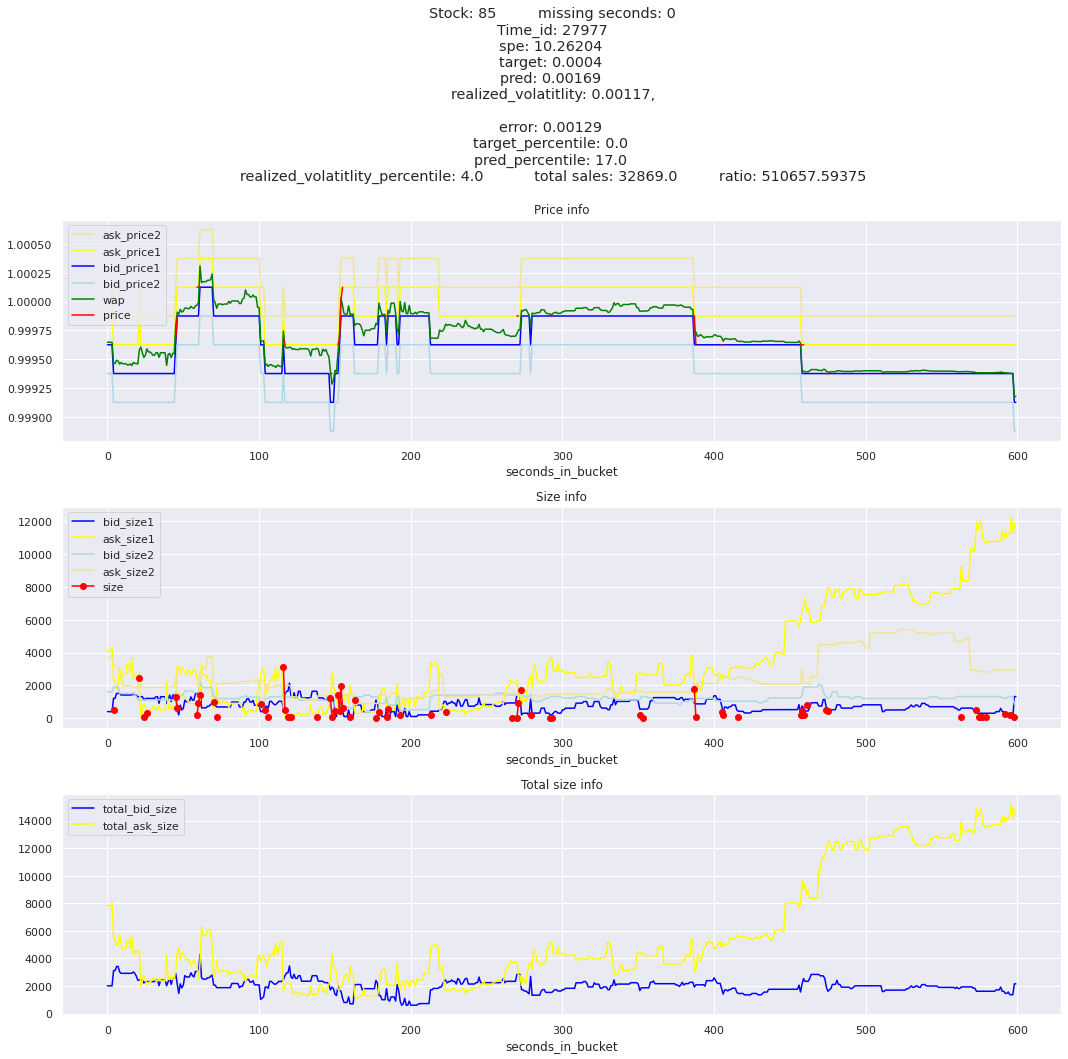
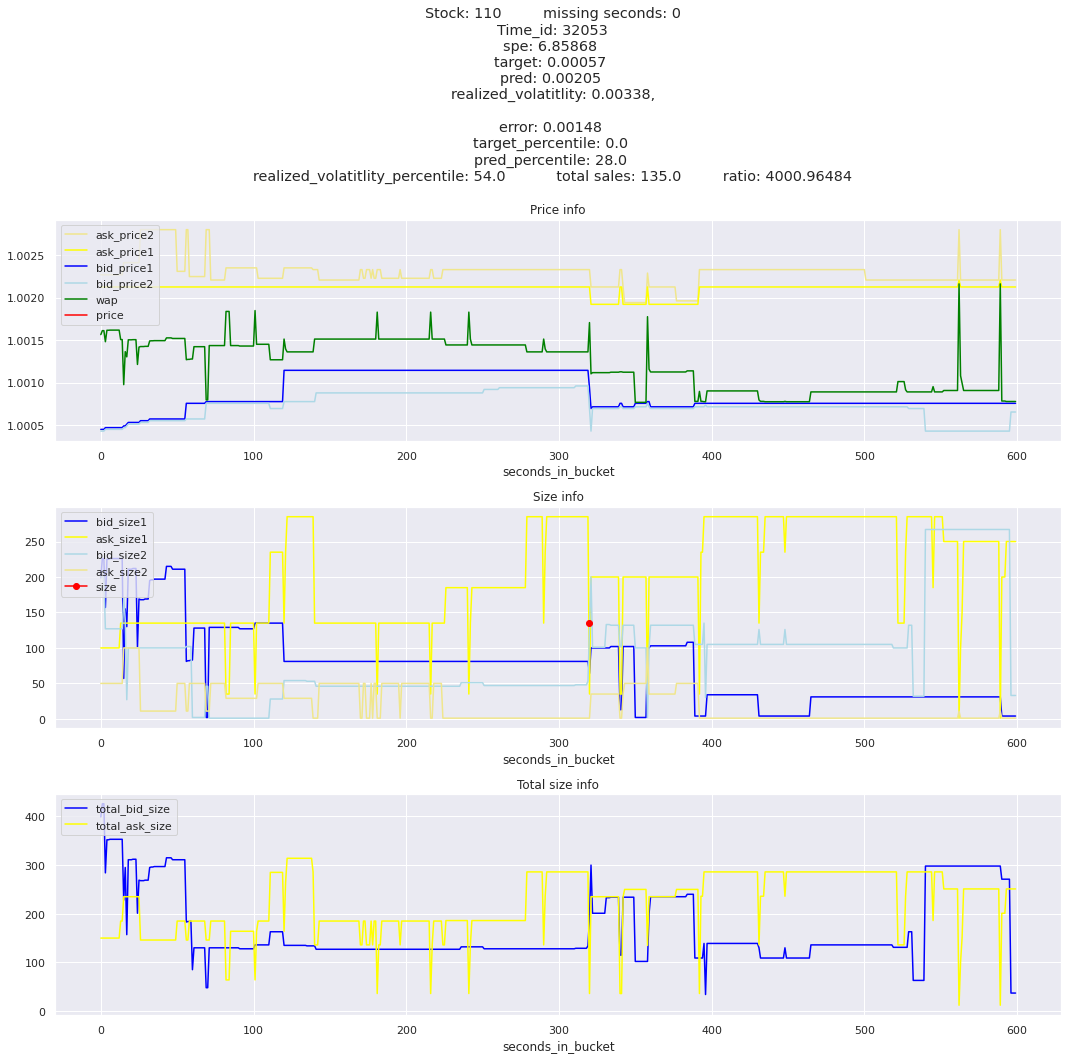
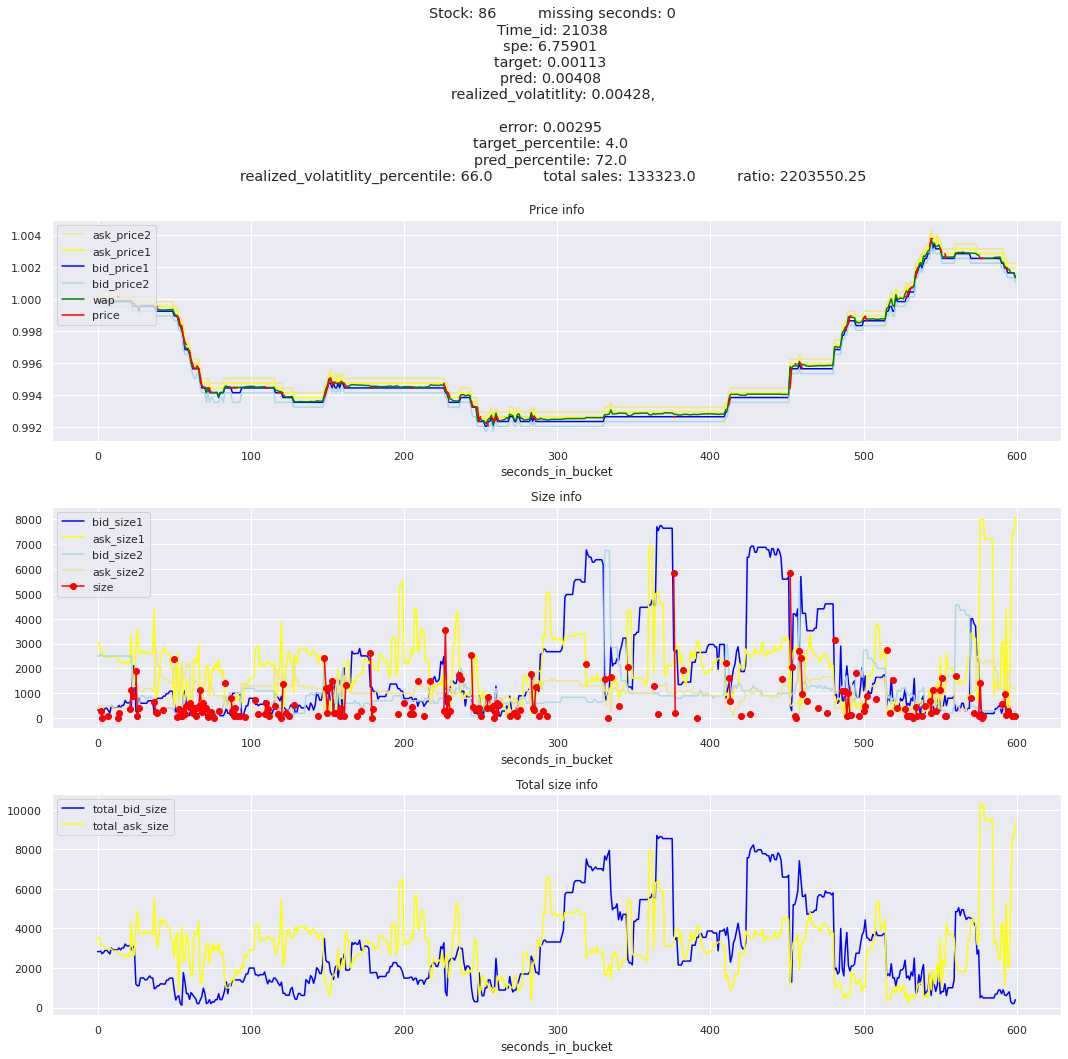
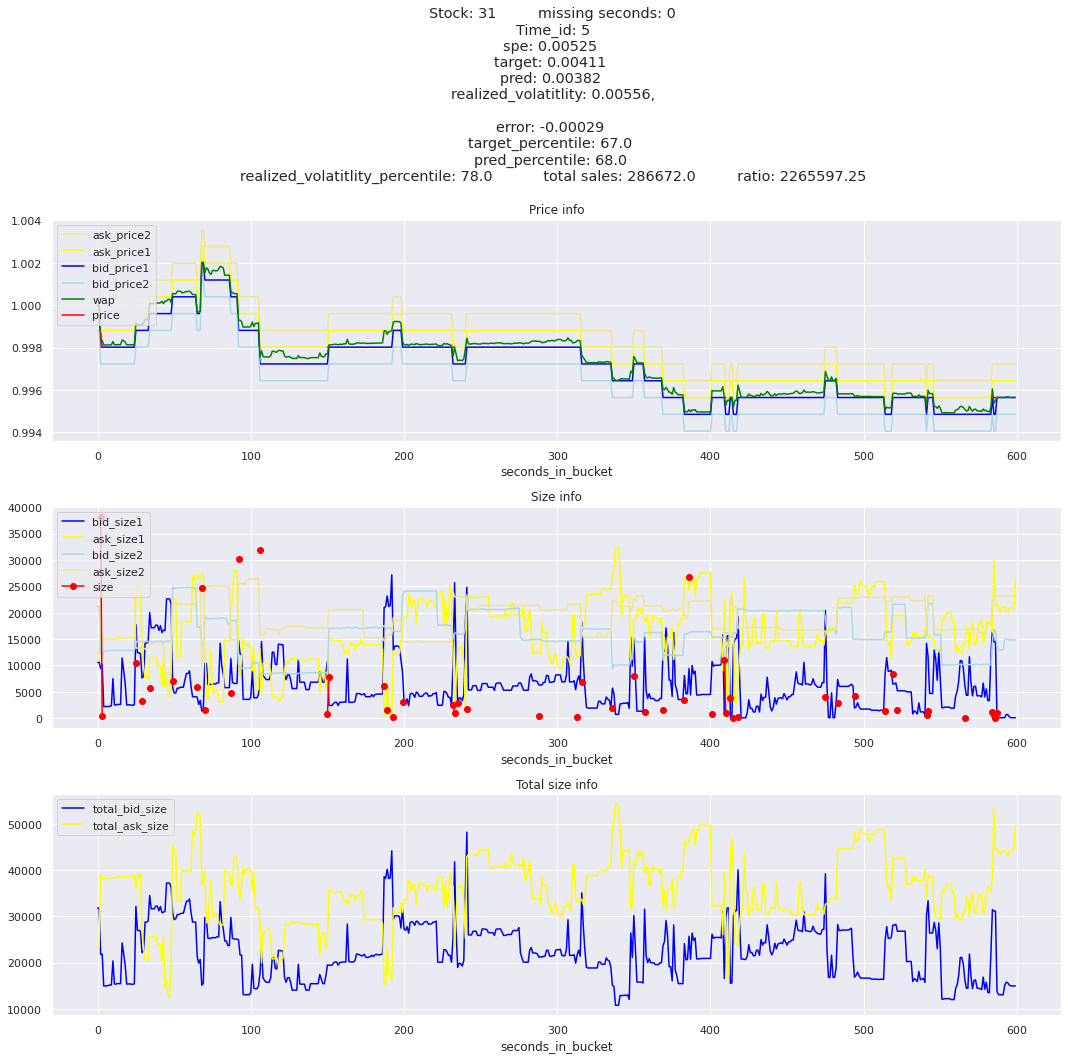
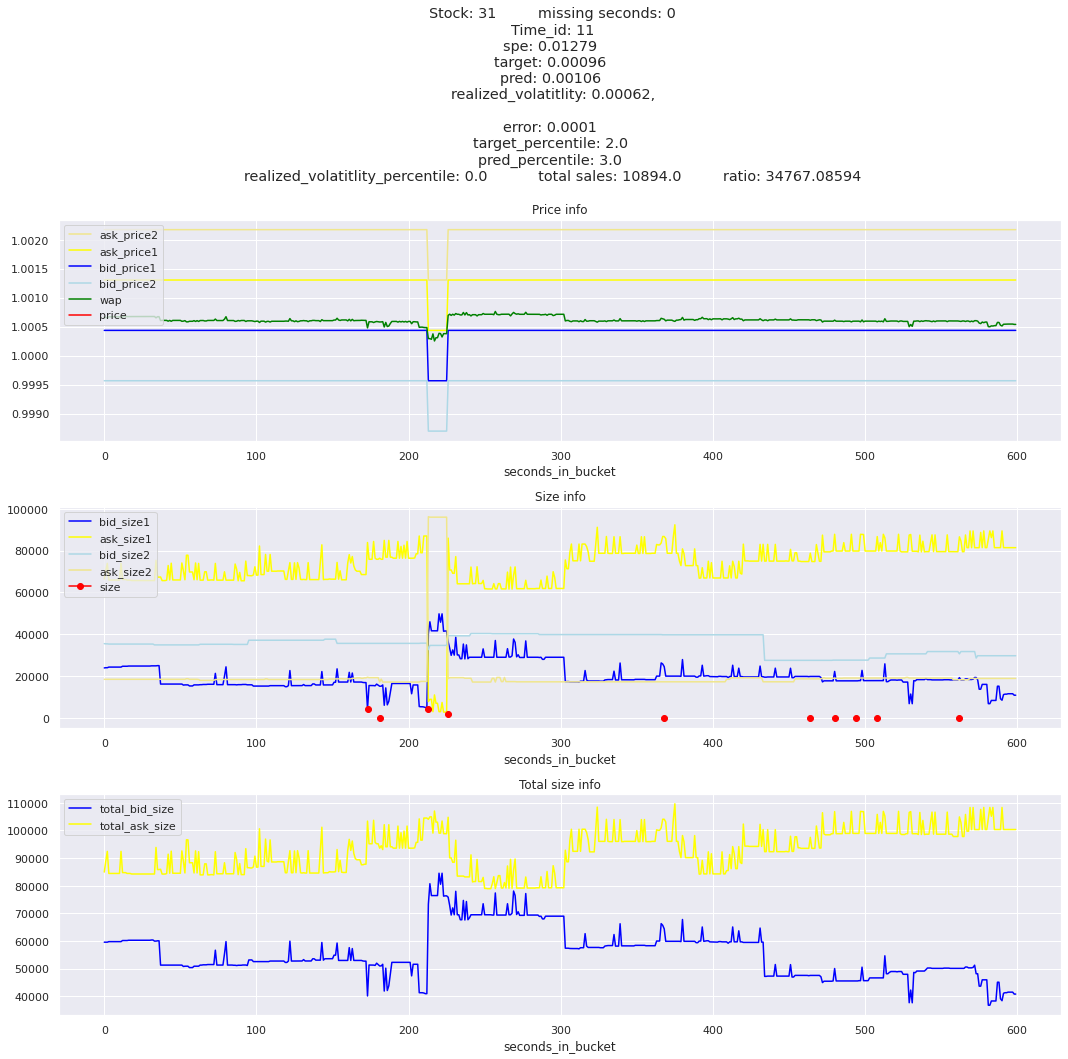
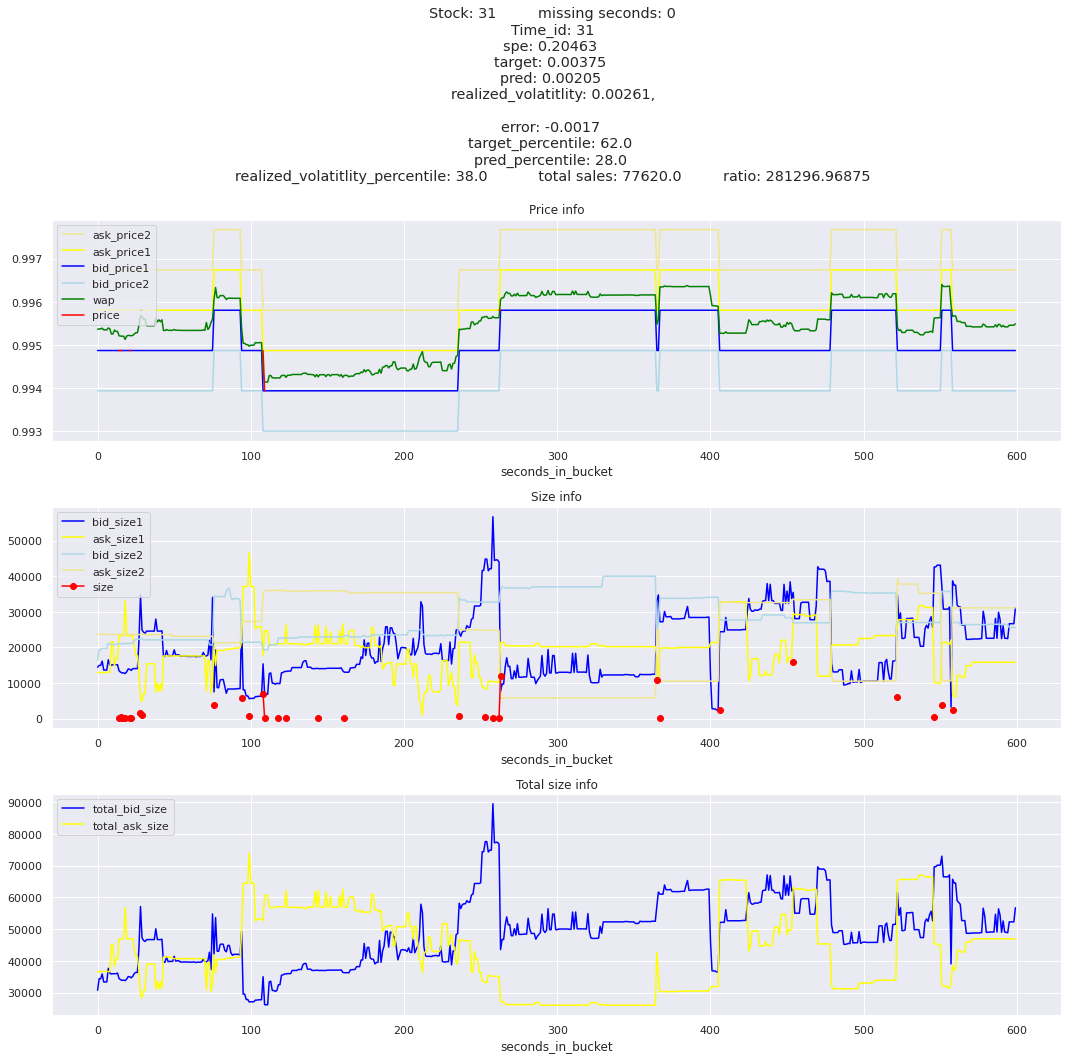
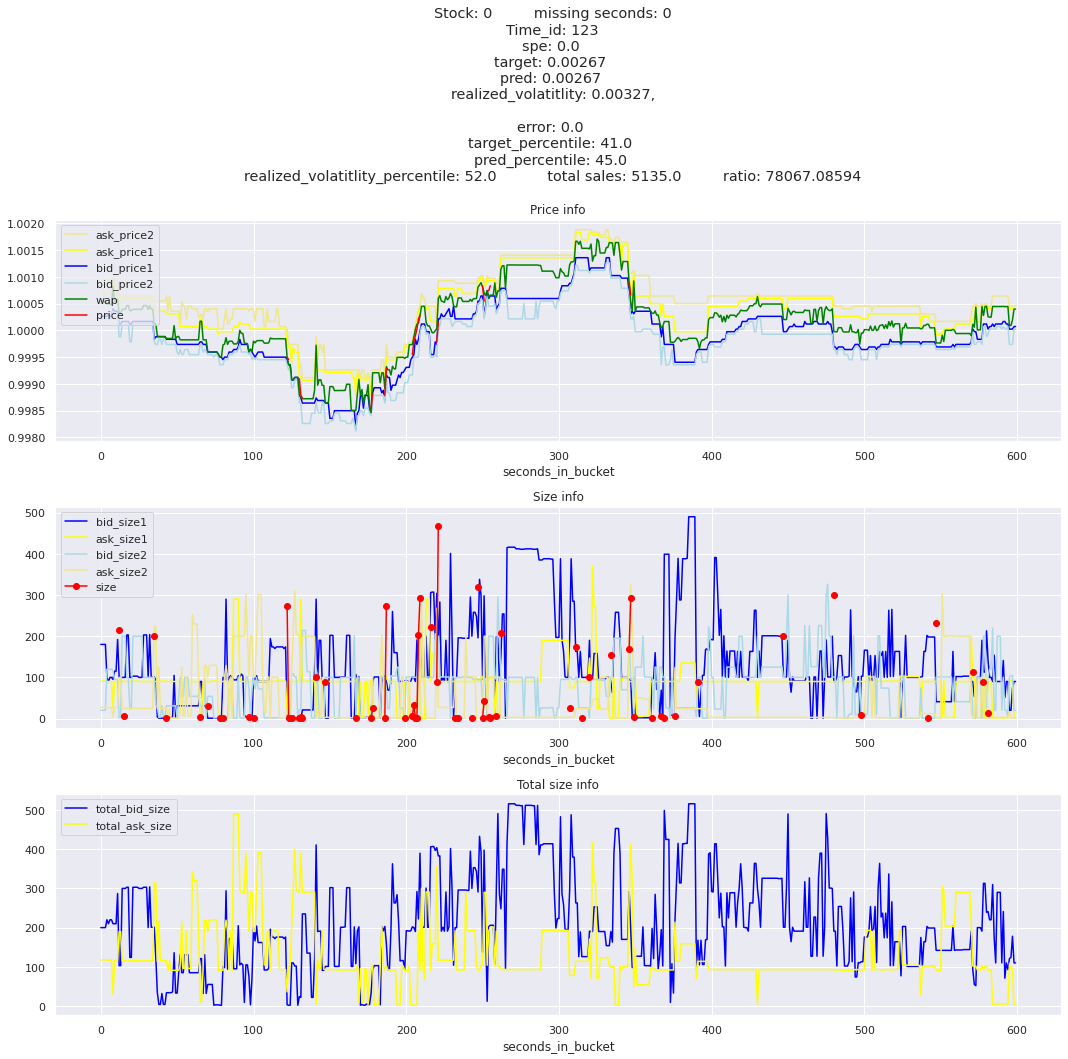
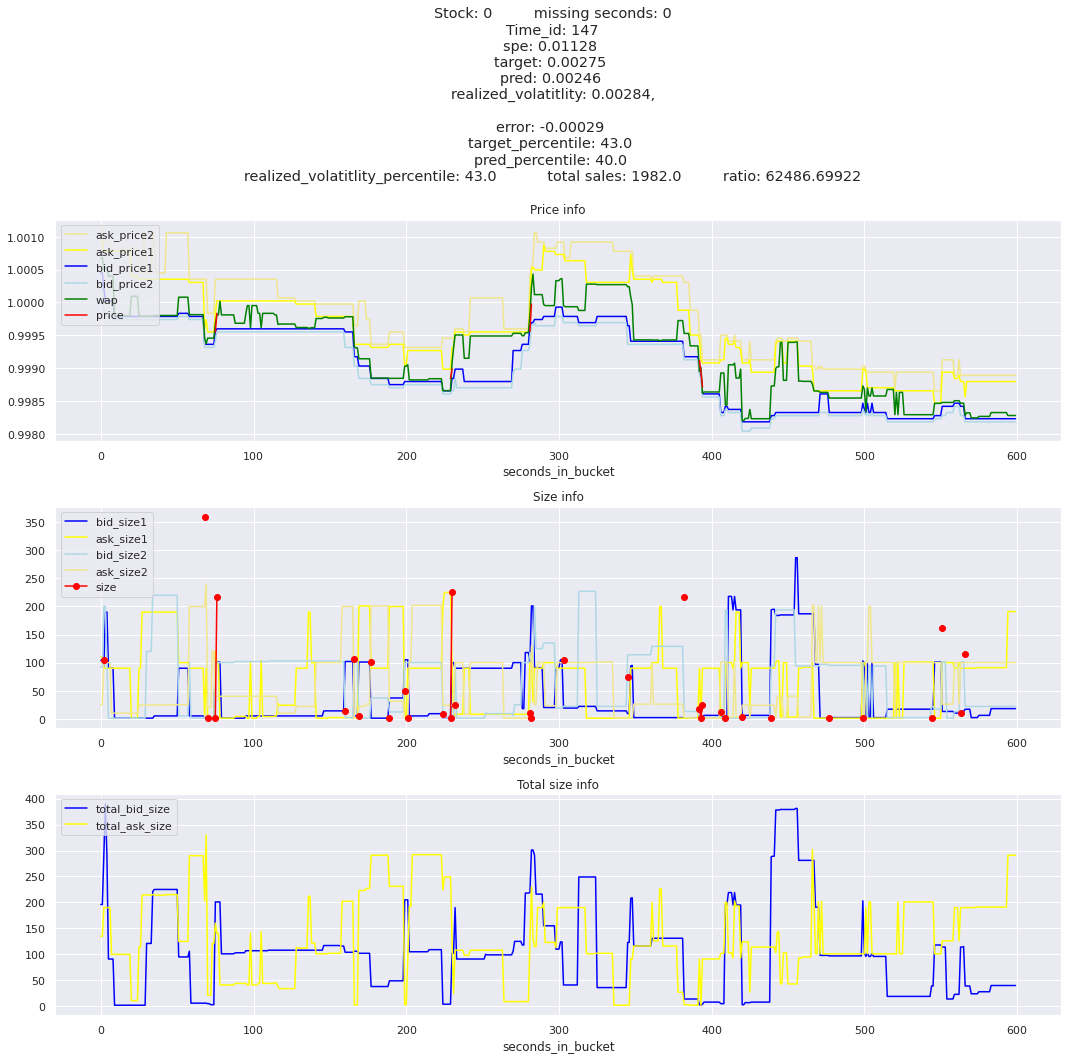
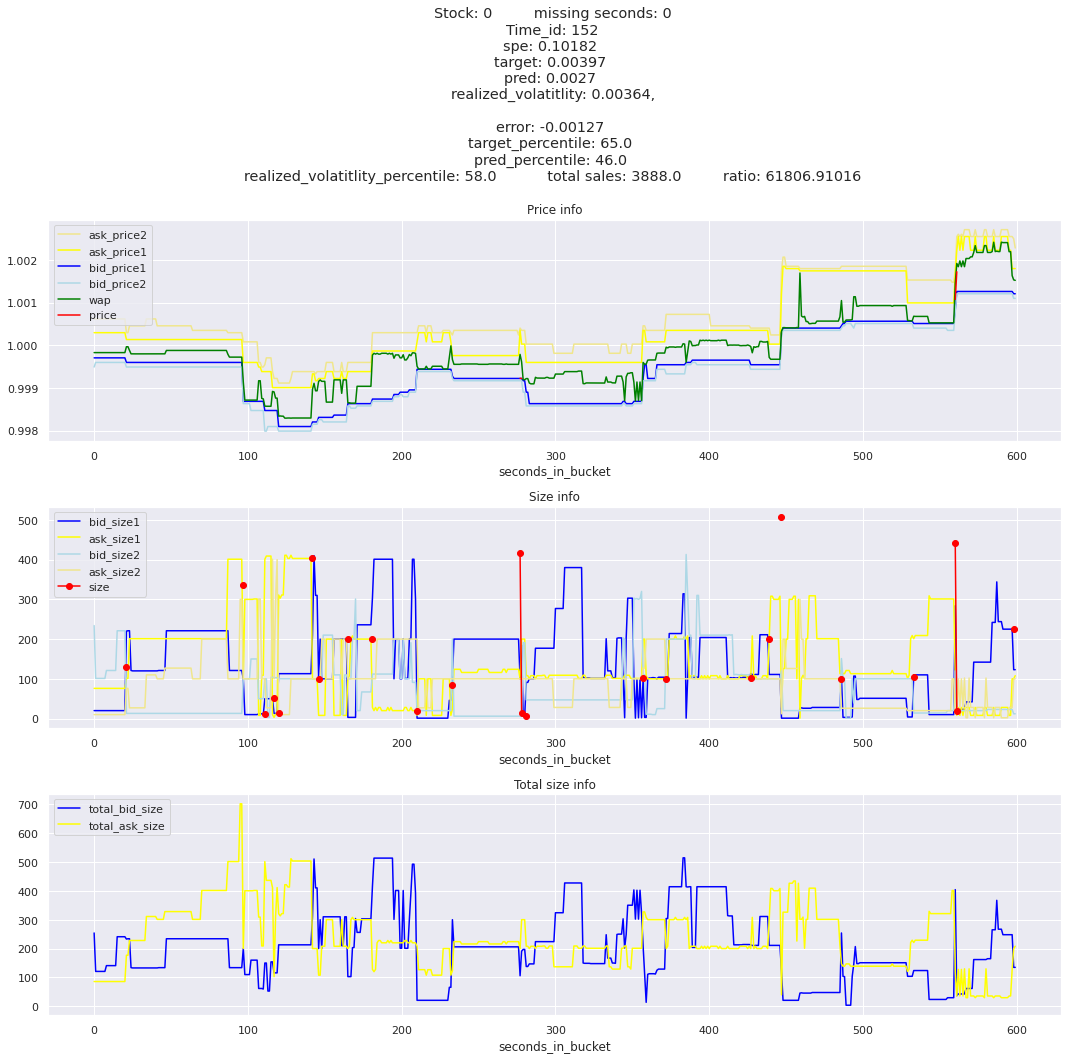
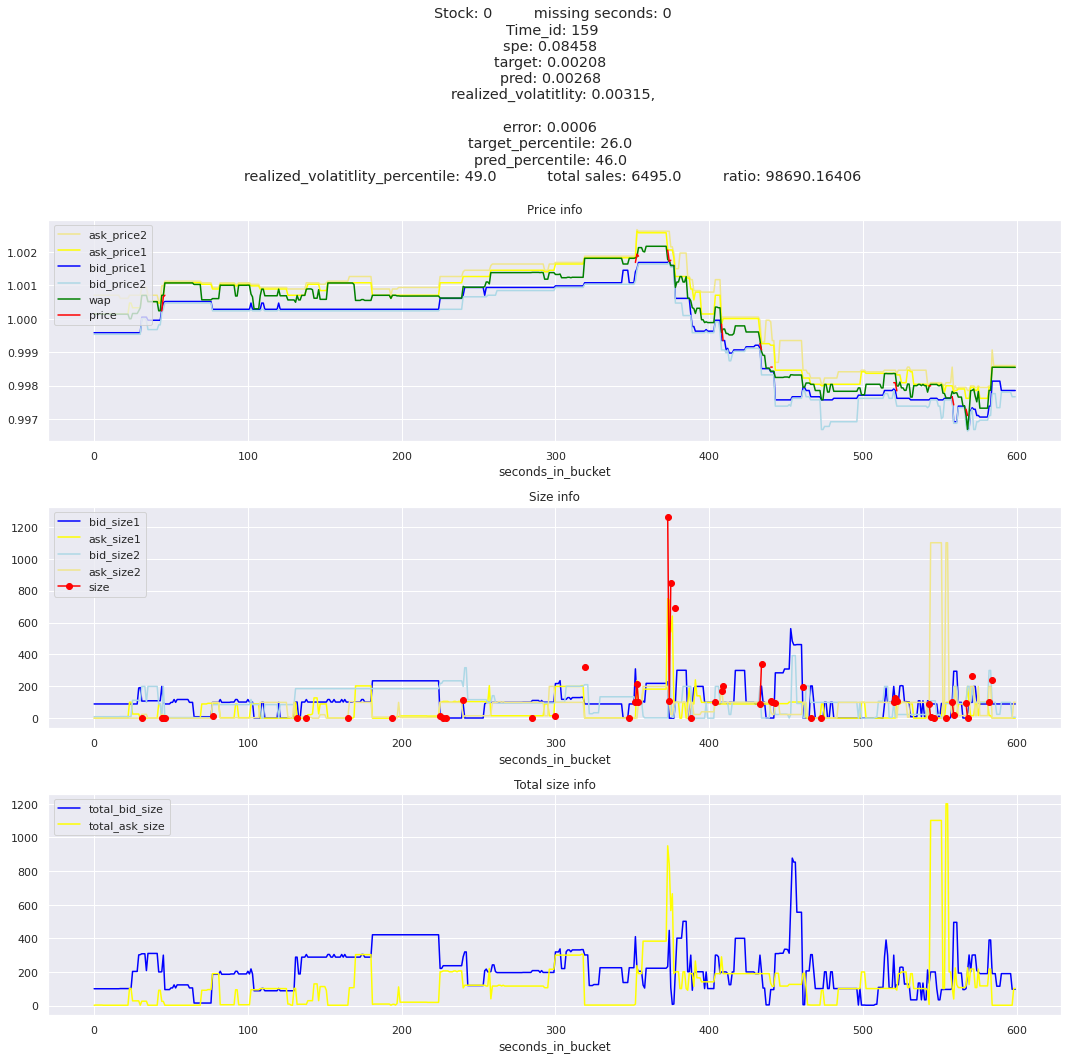
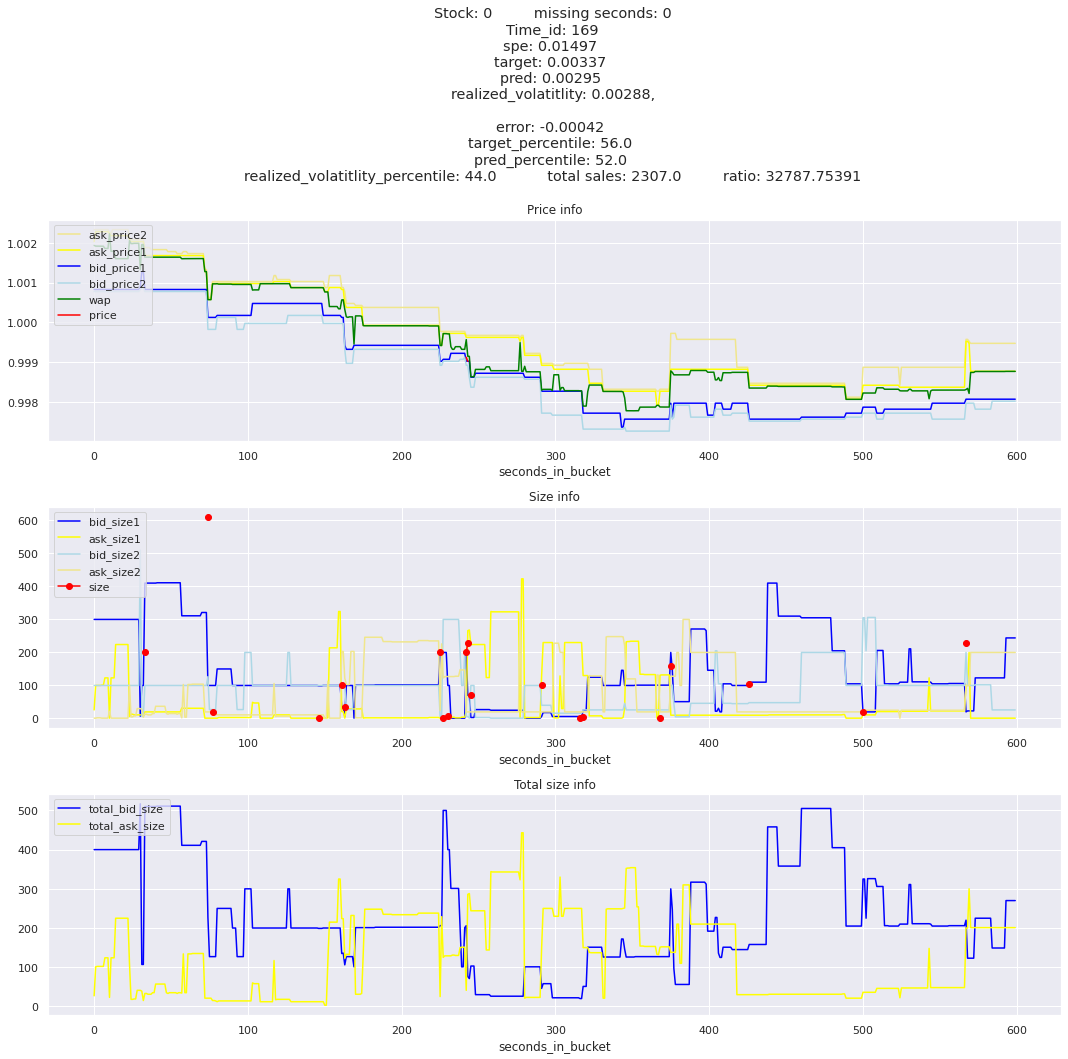
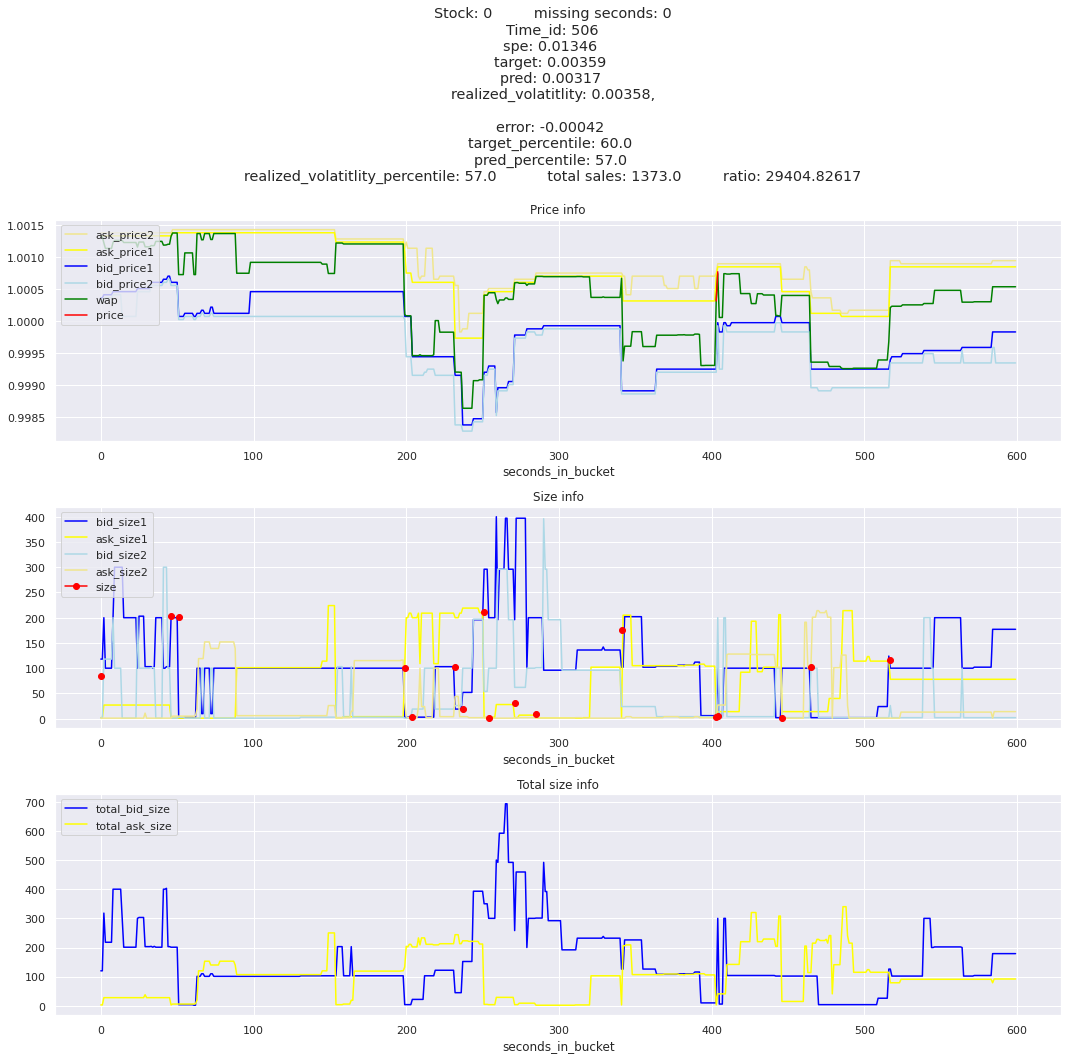
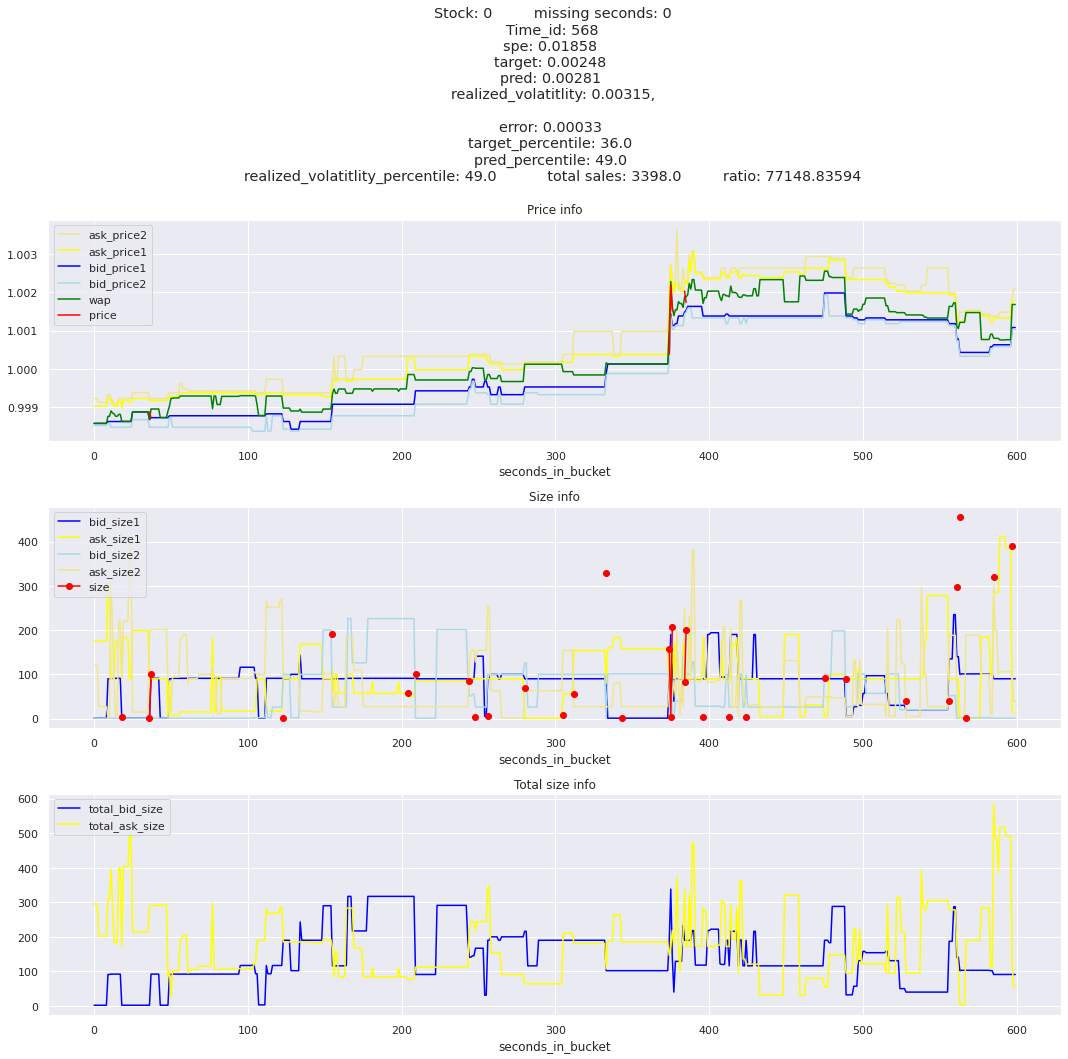
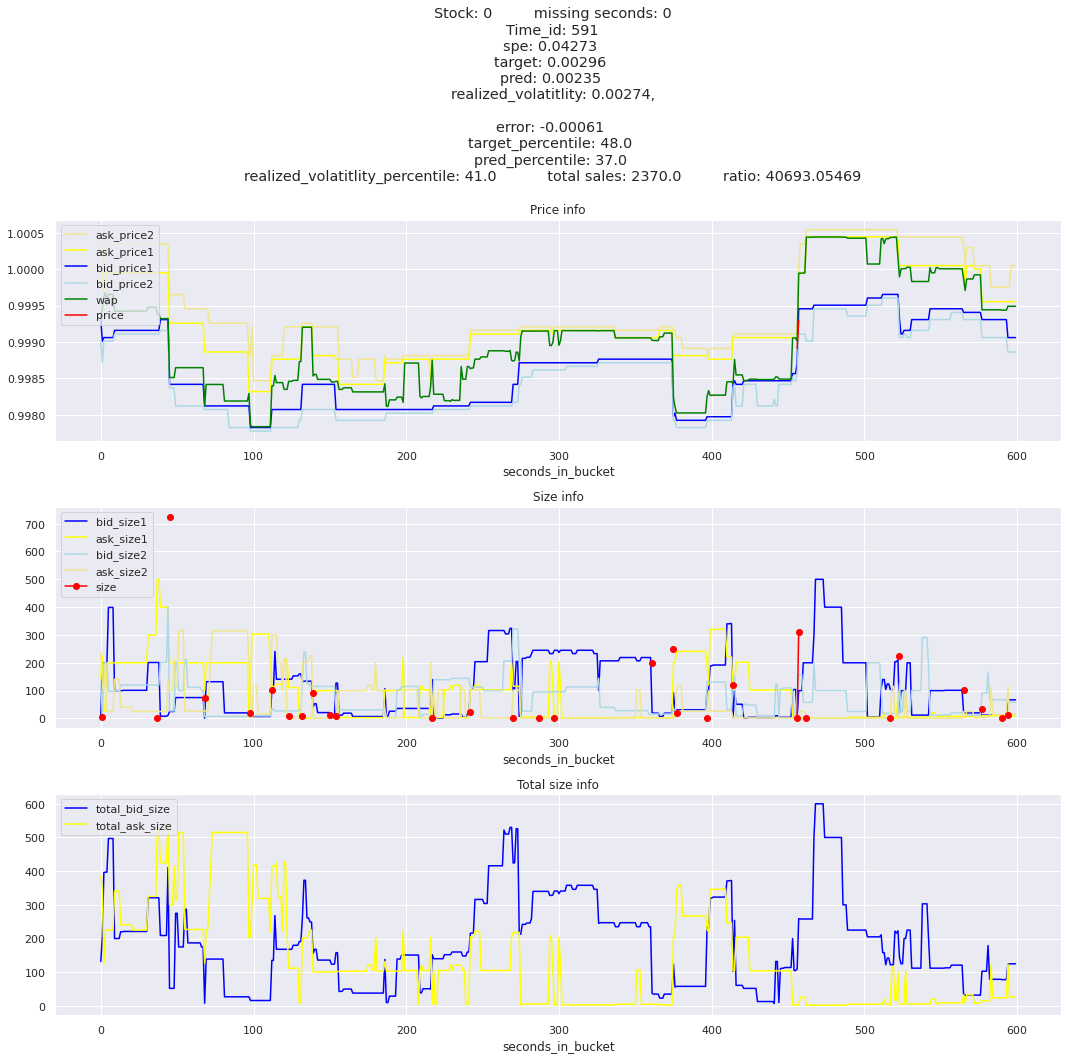
for stock_id, time_id in train.sort_values('d', ascending=False)[['stock_id', 'time_id']].values[: 10]: plot_book(stock_id, time_id)
def mean_decay(x, decay=.9, step=-1, axis=0): """Returns sum with exponential decay, step = -1 for the end of the array to matter the most.""" weights = np.power(decay, np.arange(x.shape[axis])[::step]).astype(np.float32)return np.sum(weights * x, axis=axis) / weights.sum()
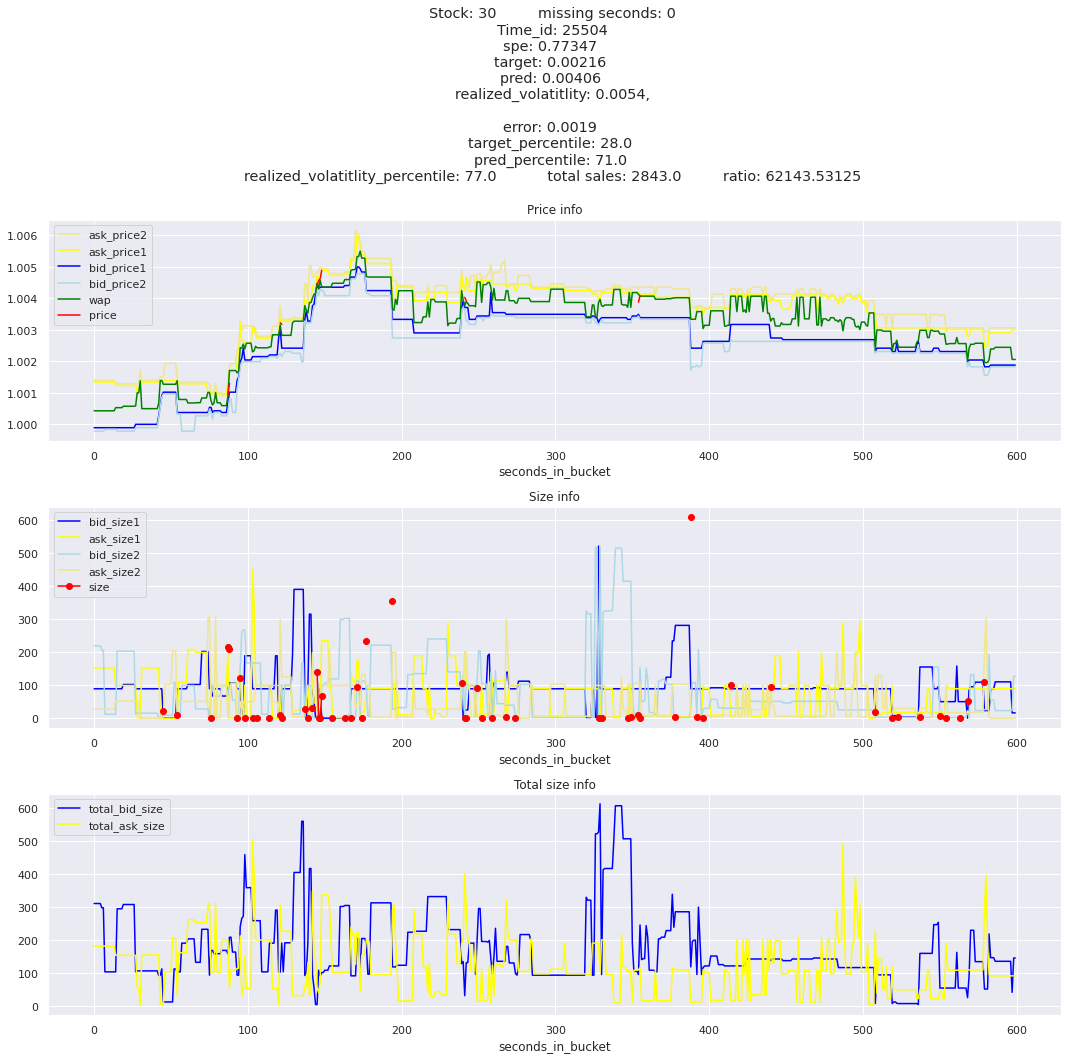
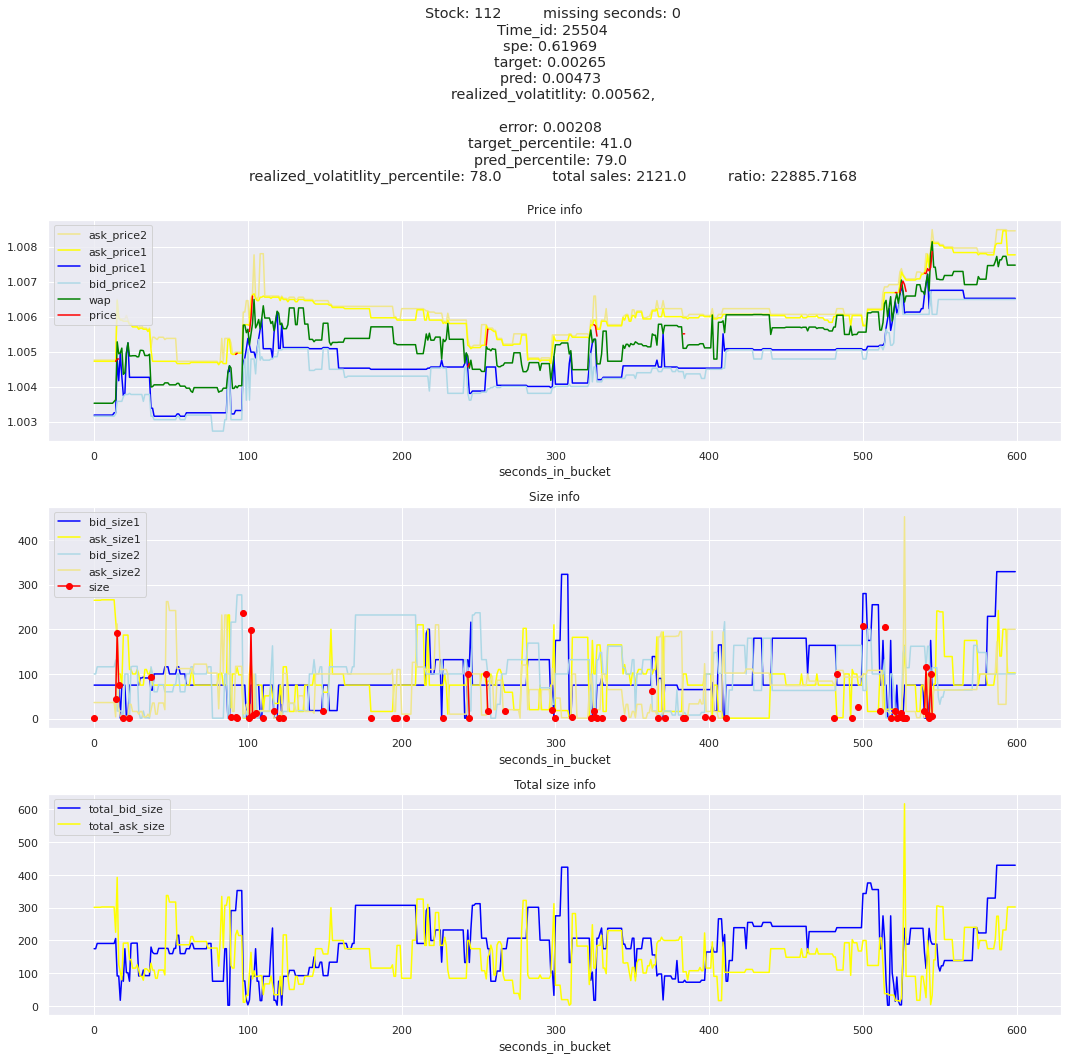
Plotting top 3 instances for each of the top 5 worst scoring time_ids
for t in top_5_worst_times: tmp = train[train.time_id == t].sort_values('spe', ascending=False)for stock_id, time_id in tmp[['stock_id', 'time_id']].values[: 3]: plot_book(stock_id, time_id)
Lets look at the most penalized instances and see if we can see a pattern.